الگوریتم بیشینه سازی انتظار EM
دسامبر 2, 2022الگوریتم EM (Expectation-Maximization)
دسامبر 4, 2022الگوریتم K-نزدیکترین همسایه (KNN)
الگوریتم K-نزدیکترین همسایه (KNN) K-Nearest Neighbor یکی از ساده ترین الگوریتم های یادگیری ماشین بر اساس تکنیک یادگیری نظارت شده است. که می تواند هم برای طبقه بندی و هم برای مسائل پیش بینی رگرسیون استفاده شود. با این حال، عمدتا برای طبقه بندی استفاده می شود. دو ویژگی زیر KNN را به خوبی تعریف می کنند
الگوریتم K-NN تمام داده های موجود را ذخیره می کند و یک نقطه داده جدید را بر اساس شباهت با داده های قبلی طبقه بندی می کند.میزان شباهت را بر اساس فاصله می سنجد. انواع فاصله ها می توانند در این روش استفاده شوند.
الگوریتم یادگیری تنبل – KNN یک الگوریتم یادگیری تنبل است زیرا مرحله آموزشی تخصصی ندارد و از تمام داده ها برای آموزش در هنگام طبقه بندی استفاده می کند. یعنیاز مجموعه آموزشی چیزی یاد نمیگیرد، در عوض مجموعه داده را ذخیره میکند و در زمان طبقهبندی، عملی را روی مجموعه داده انجام میدهد.
K-NN یک الگوریتم ناپارامتریک است، به این معنی که هیچ فرضی در مورد داده های اساسی ایجاد نمی کند.
الگوریتم KNN در مرحله آموزش فقط مجموعه داده را ذخیره می کند و هنگامی که داده های جدید دریافت می کند، آن داده ها را در دسته ای طبقه بندی می کند که بسیار شبیه به داده های جدید است.
کار الگوریتم KNN
الگوریتم K-نزدیکترین همسایه (KNN) از «شباهت ویژگی» برای پیشبینی مقادیر نقاط داده جدید استفاده میکند که به این معنی است که به نقطه داده جدید بر اساس میزان تطابق نزدیک با نقاط مجموعه آموزشی، مقداری نسبت داده میشود. با کمک مراحل زیر می توانیم کارکرد آن را درک کنیم
مرحله 1 – برای پیاده سازی هر الگوریتم، به مجموعه داده نیاز داریم. بنابراین در مرحله اول KNN، باید آموزش و همچنین داده های آزمایشی را بارگذاری کنیم.
مرحله 2 – در مرحله بعد، باید مقدار K یعنی نزدیکترین نقاط داده را انتخاب کنیم. K می تواند هر عدد صحیحی باشد.
مرحله 3 – برای هر نقطه از داده های آزمون موارد زیر را انجام دهید –
3.1 – فاصله بین داده های آزمون و هر یک از داده های آموزشی را با کمک هر یک از روش های زیر محاسبه کنید: فاصله اقلیدسی، منهتن یا همینگ. متداول ترین روش برای محاسبه فاصله اقلیدسی است.
3.2 – اکنون بر اساس مقدار فاصله، آنها را به ترتیب صعودی مرتب کنید.
3.3 – در مرحله بعد، K ردیف بالایی را از آرایه مرتب شده انتخاب می کند.
3.4 – اکنون، کلاسی را بر اساس پرتکرارترین کلاس این ردیف ها به نقطه آزمایش اختصاص می دهد.
مرحله 4 – پایان
مثال
مثال زیر برای درک مفهوم K و عملکرد الگوریتم KNN – است
فرض کنید مجموعه داده ای داریم که می توان آن را به صورت زیر ترسیم کرد
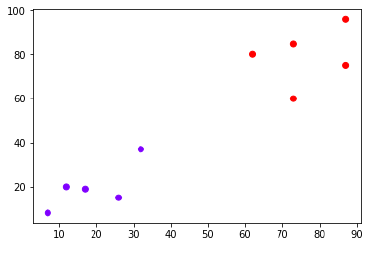
اکنون، ما باید نقطه داده جدید را با نقطه سیاه (در نقطه 60،60) به کلاس آبی یا قرمز طبقه بندی کنیم. ما K = 3 را فرض می کنیم، یعنی سه نقطه داده نزدیک را پیدا می کند. در نمودار بعدی − نشان داده شده است
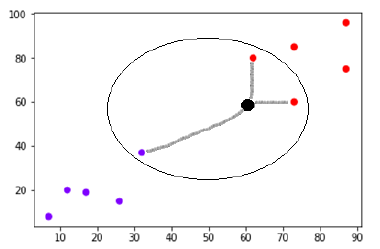
در نمودار بالا می توانیم سه همسایه نزدیک نقطه داده را با نقطه سیاه ببینیم. در بین این سه، دو نفر از آنها در کلاس قرمز قرار دارند، بنابراین نقطه سیاه نیز در کلاس قرمز اختصاص داده می شود.
چرا به الگوریتم K-NN نیاز داریم؟
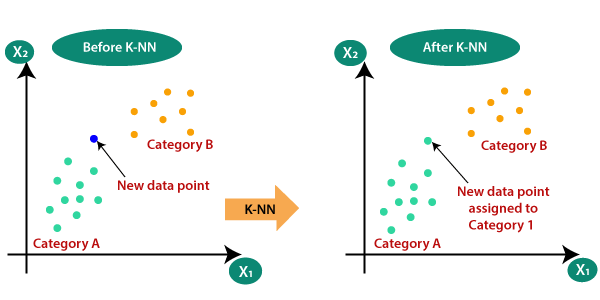
فرض کنید دو دسته وجود دارد، یعنی کلاس A و کلاس B، و ما یک نقطه داده جدید x1 داریم، این نقطه داده در کدام یک از این دسته ها قرار می گیرد. برای حل این نوع مسائل به یک الگوریتم K-NN نیاز داریم. با کمک K-NN، ما به راحتی می توانیم دسته یا کلاس یک مجموعه داده خاص را شناسایی کنیم. نمودار زیر را در نظر بگیرید: