
گام به گام اولین شبکه عصبی خود را با PyTorch توسعه دهید
آگوست 22, 2023آموزش یک شبکه عصبی متراکم ساده بینایی ماشین برای تشخیص اعداد دست نویس در پایتورچ
آگوست 24, 2023بینایی ماشین با پایتورچ
معرفی
یکی از شاخه های موفق هوش مصنوعی بینایی کامپیوتری است که به کامپیوتر اجازه می دهد تا بینش هایی را از تصاویر دیجیتال و/یا ویدئو به دست آورد. شبکه های عصبی را می توان با موفقیت برای کارهای بینایی کامپیوتری استفاده کرد.
تصور کنید در حال توسعه سیستمی برای تشخیص متن چاپ شده هستید. شما از برخی رویکردهای الگوریتمی برای تراز کردن صفحه و برش نویسه های جداگانه در متن استفاده کرده اید و اکنون باید حروف جداگانه را تشخیص دهید. این مسئله طبقه بندی تصاویر نامیده می شود، زیرا باید تصاویر ورودی را به کلاس های مختلف جدا کنیم. نمونه های دیگر چنین مسئله ای می تواند مرتب کردن خودکار کارت پستال ها بر اساس تصویر یا تعیین نوع محصول در سیستم تحویل از روی عکس باشد.
در این نوشته، نحوه آموزش مدلهای شبکه عصبی طبقهبندی تصویر را با استفاده از PyTorch، (که یکی از محبوبترین کتابخانههای پایتون برای ساخت شبکههای عصبی است)، یاد خواهیم گرفت. ما از سادهترین مدل – یک شبکه عصبی متراکم کاملاً متصل – و از مجموعه دادههای MNIST ساده از ارقام دستنویس شروع میکنیم. سپس در مورد شبکههای عصبی کانولوشنال، که برای دریافت الگوهای دو بعدی تصویر طراحی شدهاند و به مجموعه دادههای پیچیدهتر، مثل CIFAR-10، رفته ، و در مورد انها خواهیم آموخت. در نهایت، از شبکههای از پیش آموزشدیده و انتقال یادگیری استفاده میکنیم تا بتوانیم مدلها را روی مجموعه دادههای نسبتاً کوچک آموزش دهیم.
در پایان این آموزش، میتوانید مدلهای طبقهبندی تصاویر را بر روی عکسهای دنیای واقعی، مانند مجموعه دادههای گربهها و سگها آموزش دهید و طبقهبندیکنندههای تصویر را برای سناریوهای خود توسعه دهید.
اهداف یادگیری
در این نوشته شما:
در مورد وظایف بینایی کامپیوتر که معمولاً با شبکه های عصبی حل می شوند آشنا شوید
نحوه عملکرد شبکه های عصبی کانولوشنال (CNN) را درک می کنید
آموزش یک شبکه عصبی برای تشخیص ارقام دست نویس و طبقه بندی گربه ها و سگ ها
نحوه استفاده از Transfer Learning برای حل مشکلات طبقه بندی دنیای واقعی با PyTorch را می اموزید
پیش نیازها
آشنایی اولیه با نوت بوک های پایتون و ژوپیتر
آشنایی با فریم ورک PyTorch شامل تانسورها، مبانی پس انتشار و ساخت مدل ها
درک مفاهیم یادگیری ماشین، مانند طبقه بندی، مجموعه داده آموزش/آزمایش، دقت و غیره.
خب بریم برای یادگیری اهدافمون !
بینایی کامپیوتر
Computer Vision (CV) رشتهای است که به مطالعه این موضوع میپردازد که چگونه رایانهها میتوانند درجاتی از درک را از تصاویر دیجیتال و/یا ویدیو به دست آورند. درک در این تعریف معنای نسبتاً گسترده ای دارد – می تواند از تمایز بین یک گربه و یک سگ در تصویر تا کارهای پیچیده تر مانند توصیف تصویر به زبان طبیعی متغیر باشد.
کامپیوتر ویژن. تصاویر به عنوان تانسور
Computer Vision (CV) رشتهای است که به مطالعه این موضوع میپردازد که چگونه رایانهها میتوانند درجاتی از درک را از تصاویر دیجیتال و/یا ویدیو به دست آورند. درک در این تعریف معنای نسبتاً گسترده ای دارد – می تواند از تمایز بین یک گربه و یک سگ در تصویر تا کارهای پیچیده تر مانند توصیف تصویر به زبان طبیعی متغیر باشد.
رایج ترین مسائل بینایی کامپیوتر عبارتند از:
طبقهبندی تصویر سادهترین کار است، زمانی که باید یک تصویر را به یکی از دستههای از پیش تعریفشده طبقهبندی کنیم، به عنوان مثال، یک گربه را از یک سگ در عکس تشخیص دهیم، یا یک رقم دستنویس را تشخیص دهیم.
تشخیص اشیا کار کمی دشوارتر است، که در آن ما باید اشیاء شناخته شده را روی عکس پیدا کنیم و آنها را بومی سازی کنیم، یعنی کادر مرزی را برای هر یک از اشیاء شناسایی شده برگردانیم.
تقسیم بندی شبیه به تشخیص شی است، اما به جای دادن کادر محدود، باید یک نقشه پیکسلی دقیق که هر یک از اشیاء شناسایی شده را مشخص می کند، برگردانیم.
تصویری که نشان میدهد چگونه تشخیص اشیاء بینایی کامپیوتری را میتوان با گربهها، سگها و اردکها انجام داد.
تصویر گرفته شده از دوره CS224d Stanford
ما بر روی کار طبقهبندی تصویر و نحوه استفاده از شبکههای عصبی برای حل آن تمرکز خواهیم کرد. مانند برای هر کار دیگر در یادگیری ماشین، برای آموزش مدل برای طبقه بندی تصاویر، به یک مجموعه داده برچسب دار(نظارت شده )، یعنی تعداد زیادی تصویر برای هر یک از کلاس ها نیاز داریم.
تصاویر به عنوان تانسور
بینایی کامپیوتر با تصاویر کار می کند. همانطور که احتمالا می دانید، تصاویر از پیکسل تشکیل شده اند، بنابراین می توان آنها را به عنوان مجموعه ای مستطیلی (آرایه) ازپیکسل در نظر گرفت.
در قسمت اول این آموزش به تشخیص ارقام دست نویس می پردازیم. ما از مجموعه داده MNIST استفاده خواهیم کرد، که شامل تصاویر خاکستری از ارقام دست نویس، 28×28 پیکسل است. هر تصویر را می توان به صورت آرایه 28×28 نشان داد، و عناصر این آرایه نشان دهنده شدت پیکسل متناظر است – یا در مقیاس محدوده 0 تا 1 (در این حالت از اعداد ممیز شناور استفاده می شود)، یا 0 تا 255 (اعداد صحیح). یک کتابخانه محبوب پایتون به نام numpy اغلب برای وظایف بینایی کامپیوتری استفاده می شود، زیرا اجازه می دهد تا با آرایه های چند بعدی به طور موثر کار کنید.
برای تصاویر رنگی، به روشی برای نمایش رنگ ها نیاز داریم. در بیشتر موارد، هر پیکسل را با 3 مقدار شدت روشنایی نشان میدهیم که مربوط به اجزای قرمز (R)، سبز (G) و آبی (B) است. این رمزگذاری رنگی RGB نامیده می شود و بنابراین تصویر رنگی با اندازه W×H به صورت آرایه ای با اندازه 3×H×W نشان داده می شود (گاهی اوقات ممکن است ترتیب اجزا متفاوت باشد، اما ایده یکسان است).
استفاده از آرایه های چند بعدی برای نمایش تصاویر نیز مزیتی دارد، زیرا می توانیم از یک بعد اضافی برای ذخیره دنباله ای از تصاویر استفاده کنیم. به عنوان مثال، برای نمایش یک قطعه ویدیویی متشکل از 200 فریم با ابعاد 800×600، ممکن است از تانسور اندازه 200x3x600x800 استفاده کنیم.
به آرایه های چند بعدی تانسور نیز می گویند. معمولاً وقتی در مورد چارچوب شبکه عصبی مانند PyTorch صحبت می کنیم به تانسورها مراجعه می کنیم. تفاوت اصلی بین تانسورها در PyTorch و آرایههای numpy این است که تانسورها از عملیات موازی روی GPU پشتیبانی میکنند، در صورت موجود بودن. همچنین، PyTorch عملکردهای اضافی مانند تمایز خودکار را هنگام کار بر روی تانسورها ارائه می دهد.
وارد کردن بسته ها (پکیج ها) و بارگیری مجموعه داده MNIST
!pip install -r https://raw.githubusercontent.com/MicrosoftDocs/pytorchfundamentals/main/computer-vision-pytorch/requirements.txt
#Import the packages needed.
import torch
import torchvision
import matplotlib.pyplot as plt
import numpy as np
PyTorch تعدادی مجموعه داده در دسترس که مستقیماً از کتابخانه میآیند, دارا می باشد. در اینجا ما از مجموعه داده معروف MNIST از ارقام دستنویس استفاده میکنیم که از طریق torchvison.datasets.MNIST در PyTorch در دسترس است. شیء دیتاست , داده را در قالب تصاویر Python Imagine Library (PIL) برمی گرداند که با یک پارامتر transform=ToTensor() به تانسور تبدیل می کنیم.
هنگام استفاده از نوتبوکهای خود، میتوانید با سایر مجموعههای داده داخلی، بهویژه FashionMNIST، آزمایش کنید.
from torchvision.transforms import ToTensor
data_train = torchvision.datasets.MNIST('./data',
download=True,train=True,transform=ToTensor())
data_test = torchvision.datasets.MNIST('./data',
download=True,train=False,transform=ToTensor())
نمایش مجموعه داده
اکنون که مجموعه داده را دانلود کرده ایم، می توانیم برخی از ارقام را نمایش دهیم.
fig,ax = plt.subplots(1,7)
for i in range(7):
ax[i].imshow(data_train[i][0].view(28,28))
ax[i].set_title(data_train[i][1])
ax[i].axis('off')
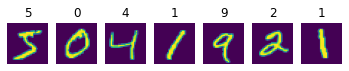
ساختار مجموعه داده
ما در مجموع 6000 تصویر آموزشی و 1000 تصویر تست داریم. مهم است که داده ها را برای آموزش و آزمایش تقسیم کنید. ما همچنین میخواهیم داده ها را کاوش کنیم تا ایده بهتری درباره شکل دادههایمان به دست آوریم
هر نمونه یک تاپل در ساختار زیر است:
عنصر اول تصویر واقعی یک رقم است که با یک تانسور به شکل 1x28x28 نشان داده شده است.
عنصر دوم برچسبی است که مشخص می کند کدام رقم توسط تانسور نمایش داده می شود. تانسوری است که دارای عددی از 0 تا 9 است.
data_train یک مجموعه داده آموزشی است که ما از آن برای آموزش مدل خود استفاده خواهیم کرد. data_test یک مجموعه داده آزمایشی کوچکتر است که می توانیم برای تأیید مدل خود از آن استفاده کنیم.
print('Training samples:',len(data_train))
print('Test samples:',len(data_test))
print('Tensor size:',data_train[0][0].size())
print('First 10 digits are:', [data_train[i][1] for i in range(10)])
Training samples: 60000
Test samples: 10000
Tensor size: torch.Size([1, 28, 28])
First 10 digits are: [5, 0, 4, 1, 9, 2, 1, 3, 1, 4]
تمام شدت پیکسل های تصاویر با مقادیر ممیز شناور بین 0 و 1 نشان داده می شود:
print('Min intensity value: ',data_train[0][0].min().item())
print('Max intensity value: ',data_train[0][0].max().item())
Min intensity value: 0.0
Max intensity value: 1.0
بارگذاری تصاویر خود
در بیشتر کاربردهای عملی، شما باید برای آموزش شبکه عصبی مد نظرتون, تصاویر را روی دیسک قرار دهید و از آنها استفاده کنید. در این مورد، باید آنها را از طریق تانسورهای PyTorch بارگذاری کنید.
یکی از راه های انجام این کار استفاده از یکی از کتابخانه های پایتون برای کار با تصویر است، مانند Open CV یا PIL/Pillow یا imageio. هنگامی که تصویر خود را در آرایه numpy بارگذاری می کنید، می توانید به راحتی آن را به تانسور تبدیل کنید.
مهم است که مطمئن شوید همه مقادیر قبل از ارسال به یک شبکه عصبی, در محدوده [0..1] مقیاسبندی شدهاند – این قرارداد معمول برای آمادهسازی دادهها است و همه مقدار اولیه پیشفرض وزن در شبکههای عصبی برای کار با این رنج طراحی شدهاند. تبدیل ToTensor که در بالا دیدیم به طور خودکار تصاویر PIL/numpy را با مقادیر پیکسل صحیح در محدوده [0..1] مقیاس میکند.
حتی رویکرد بهتر استفاده از قابلیت در کتابخانه Torchvision، یعنی ImageFolder است. تمام مراحل پیش پردازش را به صورت خودکار انجام می دهد و همچنین برچسب هایی را با توجه به ساختار دایرکتوری به تصاویر اختصاص می دهد. ما نمونه استفاده از ImageFolder را بعداً در این دوره خواهیم دید، هنگامی که شروع به طبقه بندی تصاویر گربه ها و سگ های خود می کنیم.
توجه به این نکته ضروری است که همه تصاویر باید به یک اندازه مقیاس شوند. اگر تصاویر اصلی شما نسبتهای متفاوتی دارند، باید تصمیم بگیرید که چگونه این مقیاسبندی را انجام دهید – یا با برش تصاویر یا با اضافه کردن فضای اضافی.
بردن
شبکه های عصبی با تانسورها کار می کنند و قبل از آموزش هر مدلی باید مجموعه داده خود را به مجموعه ای از تانسورها تبدیل کنیم. این اغلب مستلزم آن است که مجموعه دادههای آموزشی و آزمایشی را بارگذاری کنیم و آماده شروع آموزش اولین شبکه عصبی خود شویم!
آموزش یک شبکه عصبی متراکم ساده
آموزش شبکه عصبی متراکم
بیایید روی مشکل تشخیص رقم دست نویس تمرکز کنیم. این یک مشکل طبقه بندی است، زیرا برای هر تصویر ورودی باید کلاس را مشخص کنیم – کدام رقم است.
در این واحد، ما با سادهترین رویکرد ممکن برای طبقهبندی تصویر – یک شبکه عصبی کاملاً متصل (که پرسپترون نیز نامیده میشود) شروع میکنیم. نحوه تعریف شبکههای عصبی در PyTorch و نحوه عملکرد الگوریتم آموزشی را مرور میکنیم. اگر با این مفاهیم آشنا هستید – به بخش بعدی بروید، جایی که ما شبکه های عصبی کانولوشنال (CNN) را معرفی می کنیم.
ما از کمک کننده «pytorchcv» برای بارگذاری تمام داده هایی که در واحد قبلی در مورد آنها صحبت کردیم استفاده می کنیم.
!wget https://raw.githubusercontent.com/MicrosoftDocs/pytorchfundamentals/main/computer-vision-pytorch/pytorchcv.py
import torch
import torch.nn as nn
import torchvision
import matplotlib.pyplot as plt
from torchinfo import summary
from pytorchcv import load_mnist, plot_results
load_mnist()
شبکه های عصبی متراکم کاملاً متصل
یک شبکه عصبی پایه در PyTorch از تعدادی لایه تشکیل شده است. ساده ترین شبکه فقط شامل یک لایه کاملا متصل است که به آن لایه خطی می گویند، با 784 ورودی (یک ورودی برای هر پیکسل تصویر ورودی) و 10 خروجی (یک خروجی برای هر کلاس).
<img alt=”گرافی که نشان می دهد چگونه یک تصویر بر اساس پیکسل ها به لایه ها تقسیم می شود.”
همانطور که در بالا توضیح دادیم، ابعاد تصاویر رقمی ما $1\times28\times28$ است، یعنی هر تصویر شامل $28\times28=784$ پیکسل متفاوت است. از آنجایی که لایه خطی ورودی خود را به صورت بردار تک بعدی انتظار میرود، باید لایه دیگری به نام Flatten را وارد شبکه کنیم تا شکل تانسور ورودی را از $1\times28\times28$ به $784$ تغییر دهیم.
بعد از «Flatten»، یک لایه خطی اصلی (به نام «Dense» در اصطلاح PyTorch) وجود دارد که 784 ورودی را به 10 خروجی تبدیل میکند – یکی برای هر کلاس. ما میخواهیم $n$-th خروجی شبکه را برگرداند تا احتمال رقم ورودی برابر با $n$ باشد.
از آنجا که خروجی یک لایه کاملاً متصل بین 0 و 1 نرمال سازی نشده است، نمی توان آن را به عنوان احتمال در نظر گرفت. علاوه بر این، اگر میخواهید خروجیها احتمالات ارقام مختلف باشند، همه آنها باید تا 1 جمع شوند. برای تبدیل بردارهای خروجی به بردار احتمال، تابعی به نام Softmax اغلب به عنوان آخرین تابع فعالسازی در شبکه عصبی طبقهبندی استفاده میشود. . برای مثال، $\mathrm{softmax}([-1,1,2]) = [0.035,0.25,0.705]$.
در PyTorch، ما اغلب ترجیح می دهیم از تابع LogSoftmax استفاده کنیم، که لگاریتم احتمالات خروجی را نیز محاسبه می کند. برای تبدیل بردار خروجی به احتمالات واقعی، باید torch.exp را از خروجی بگیریم.
بنابراین، معماری شبکه ما را می توان با دنباله لایه های زیر نشان داد:

می توان آن را در PyTorch به روش زیر با استفاده از نحو “Sequential” تعریف کرد:
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784,10), # 784 inputs, 10 outputs
nn.LogSoftmax())
این دنباله از لایه ها در زیر با جزئیات بیشتر نشان داده شده است. برای همه بردارها در این نمودار اندازه تانسور را نیز نشان می دهیم.

در سمت راست این نمودار، خروجی مورد انتظار شبکه را نیز داریم که به صورت برداریکی روشن کدگذاری شده نشان داده شده است. خروجی مورد انتظار با خروجی واقعی شبکه ما با استفاده از ** تابع ضرر** مقایسه می شود که یک عدد – ضرر – را به عنوان خروجی می دهد. هدف ما در طول آموزش شبکه این است که با تنظیم پارامترهای مدل – وزن لایه ها، این تلفات را به حداقل برسانیم.
آموزش شبکه
شبکه ای که به این شکل تعریف می شود می تواند هر رقمی را به عنوان ورودی بگیرد و بردار احتمالات را به عنوان خروجی تولید کند. بیایید ببینیم این شبکه با دادن یک رقم از مجموعه داده ما چگونه عمل می کند:
print('Digit to be predicted: ',data_train[0][1])
torch.exp(net(data_train[0][0]))
رقم قابل پیش بینی: 5
C:\winapp\Miniconda3\envs\py38\lib\site-packages\torch\nn\modules\container.py:119: هشدار کاربر: انتخاب بعد ضمنی برای log_softmax منسوخ شده است. فراخوانی را تغییر دهید تا dim=X را به عنوان آرگومان درج کند.
ورودی = ماژول (ورودی)
tensor([[0.1174, 0.1727, 0.0804, 0.1333, 0.0790, 0.0902, 0.0657, 0.0871, 0.0807,
0.0933]], grad_fn=<ExpBackward>)
از آنجا که ما از LogSoftmax به عنوان فعال سازی نهایی شبکه خود استفاده می کنیم، خروجی شبکه را از طریق torch.exp برای بدست آوردن احتمالات عبور می دهیم.
همانطور که می بینید شبکه احتمالات مشابهی را برای هر رقم پیش بینی می کند. این به این دلیل است که در مورد نحوه تشخیص ارقام آموزش ندیده است. ما باید داده های آموزشی خود را برای آموزش به آن بدهیم
برای آموزش مدل باید دسته هایی از مجموعه داده هایمان با اندازه معین، مثلاً 64 ایجاد کنیم. PyTorch یک شی به نام DataLoader دارد که می تواند دسته هایی از داده های ما را به طور خودکار برای ما ایجاد کند:
train_loader = torch.utils.data.DataLoader(data_train,batch_size=64)
test_loader = torch.utils.data.DataLoader(data_test,batch_size=64) # we can use larger batch size for testing
مراحل فرآیند آموزش به شرح زیر است:
ما یک minibatch از مجموعه داده ورودی می گیریم که شامل داده های ورودی (ویژگی ها) و نتیجه مورد انتظار (برچسب) است.
ما نتیجه پیش بینی شده را برای این مینی بچ محاسبه می کنیم.
تفاوت بین این نتیجه و نتیجه مورد انتظار با استفاده از یک تابع خاص به نام تابع ضرر محاسبه می شود. تابع Loss نشان می دهد که خروجی شبکه چقدر با خروجی مورد انتظار متفاوت است. هدف از آموزش ما به حداقل رساندن ضرر است. ما گرادیان های این تابع تلفات را با توجه به وزن مدل (پارامترها) محاسبه می کنیم، که سپس برای تنظیم وزن ها برای بهینه سازی عملکرد شبکه استفاده می شود. میزان تنظیم توسط پارامتری به نام نرخ یادگیری کنترل می شود و جزئیات الگوریتم بهینه سازی در شی بهینه ساز تعریف می شود.
ما آن مراحل را تکرار می کنیم تا کل مجموعه داده پردازش شود. یک گذر کامل از مجموعه داده، دوره نامیده می شود.
در اینجا یک تابع است که آموزش یک دوره را انجام می دهد:
def train_epoch(net,dataloader,lr=0.01,optimizer=None,loss_fn = nn.NLLLoss()):
optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)
net.train()
total_loss,acc,count = 0,0,0
for features,labels in dataloader:
optimizer.zero_grad()
out = net(features)
loss = loss_fn(out,labels) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
total_loss+=loss
_,predicted = torch.max(out,1)
acc+=(predicted==labels).sum()
count+=len(labels)
return total_loss.item()/count, acc.item()/count
train_epoch(net,train_loader)
(0.0059344619750976565, 0.8926833333333334)
از آنجایی که این تابع بسیار عمومی است، میتوانیم بعداً از آن در نمونههای دیگرمان استفاده کنیم. تابع پارامترهای زیر را می گیرد:
شبکه عصبی
DataLoader که داده هایی را برای آموزش تعریف می کند
Loss Function که تابعی است که تفاوت بین نتیجه مورد انتظار و نتیجه تولید شده توسط شبکه را اندازه گیری می کند. در اکثر وظایف طبقه بندی NLLLoss استفاده می شود، بنابراین ما آن را به صورت پیش فرض در نظر می گیریم.
بهینه ساز، که یک الگوریتم بهینه سازی را تعریف می کند. سنتی ترین الگوریتم، نزول گرادیان تصادفی است، اما ما به طور پیش فرض از نسخه پیشرفته تری به نام Adam استفاده خواهیم کرد.
نرخ یادگیری سرعت یادگیری شبکه را مشخص می کند. در طول یادگیری، دادههای یکسانی را چندین بار نشان میدهیم و هر بار وزنها تنظیم میشوند. اگر نرخ یادگیری خیلی بالا باشد، مقادیر جدید دانش را از مقادیر قدیمی بازنویسی میکند و شبکه عملکرد بدی خواهد داشت. اگر میزان یادگیری خیلی کم باشد، فرآیند یادگیری بسیار کندی را به همراه دارد.
این چیزی است که ما هنگام آموزش انجام می دهیم:
تغییر شبکه به حالت آموزشی (net.train())
تمام دستههای موجود در مجموعه داده را مرور کنید و برای هر دسته موارد زیر را انجام دهید:
محاسبه پیشبینیهای انجامشده توسط شبکه در این دسته (خروج)
محاسبه ضرر، که اختلاف بین مقادیر پیش بینی شده و مورد انتظار است
سعی کنید با تنظیم وزن شبکه تلفات را به حداقل برسانید (optimizer.step())
محاسبه تعداد موارد به درستی پیش بینی شده (دقت)
این تابع میانگین تلفات هر مورد داده و دقت آموزش (درصد موارد به درستی حدس زده شده) را محاسبه و برمی گرداند. با مشاهده این از دست دادن در حین آموزش می توان متوجه شد که آیا شبکه در حال بهبود است و از داده های ارائه شده یاد می گیرد یا خیر.
همچنین کنترل دقت در مجموعه داده آزمایشی (که دقت اعتبارسنجی نیز نامیده می شود) مهم است. یک شبکه عصبی خوب با پارامترهای زیاد می تواند با دقت مناسبی روی هر مجموعه داده آموزشی پیش بینی کند، اما ممکن است به سایر داده ها تعمیم ضعیفی داشته باشد. به همین دلیل است که در بیشتر موارد، بخشی از دادههای خود را کنار میگذاریم، و سپس به صورت دورهای بررسی میکنیم که مدل بر روی آنها چقدر خوب عمل میکند. در اینجا تابع ارزیابی شبکه در مجموعه داده آزمایشی است:
def validate(net, dataloader,loss_fn=nn.NLLLoss()):
net.eval()
count,acc,loss = 0,0,0
with torch.no_grad():
for features,labels in dataloader:
out = net(features)
loss += loss_fn(out,labels)
pred = torch.max(out,1)[1]
acc += (pred==labels).sum()
count += len(labels)
return loss.item()/count, acc.item()/count
validate(net,test_loader)