
شبکه عصبی
سپتامبر 10, 2022یادگیری عمیق در گوگل کولب
اکتبر 7, 2022مقاله LIFT: Learned Invariant Feature Transform
خلاصه.
ما یک معماری جدید Deep Network را معرفی میکنیم که مدیریت خط لوله نقطه ویژگی کامل را پیادهسازی میکند، یعنی تشخیص، تخمین جهت و توصیف ویژگی. در حالی که کارهای قبلی با موفقیت هر یک از این مشکلات را به صورت جداگانه حل کردهاند، ما نشان میدهیم که چگونه یاد بگیریم هر سه را به شیوهای یکپارچه انجام دهیم و در عین حال تمایز انتها به انتها را حفظ کنیم. سپس نشان میدهیم که خط لوله عمیق ما بدون نیاز به آموزش مجدد، از روشهای پیشرفته در تعدادی از مجموعه دادههای معیار بهتر عمل میکند.
ویژگی های محلی در بسیاری از برنامه های Computer Vision نقش کلیدی ایفا می کنند. یافتن و تطبیق آنها در بین تصاویر موضوع تحقیقات گسترده ای بوده است. تا همین اواخر، بهترین تکنیکها بر ویژگیهای با دقت دستساز تکیه داشتند [1-5]. در طول چند سال گذشته، مانند بسیاری از حوزههای بینایی کامپیوتر، روشهای مبتنی بر یادگیری ماشین، و به طور خاص یادگیری عمیق، شروع به عملکرد بهتر از این روشهای سنتی کردهاند [6-10].
با این حال، این الگوریتمهای جدید تنها به یک مرحله در زنجیره پردازش کامل میپردازند، که شامل شناسایی ویژگیها، محاسبه جهت آنها، و استخراج بازنمایی مقاوم است که به ما امکان میدهد آنها را در بین تصاویر مطابقت دهیم. در این مقاله یک معماری عمیق را معرفی می کنیم که هر سه مرحله را با هم انجام می دهد. ما نشان میدهیم که عملکرد کلی بهتری نسبت به روشهای قبلی به دست میآورد، به این دلیل که تا حد زیادی اجازه میدهد این مراحل جداگانه بهینه شوند تا در ارتباط با یکدیگر به خوبی کار کنند.
معماری ما، که ما از آن به عنوان LIFT برای تبدیل ویژگی مقاوم قابل یادگیری یاد میکنیم، در شکل 1 نشان داده شده است. از سه جزء تشکیل شده است که در ادامه هم کار می کنند: آشکارساز، برآوردگر جهت، و توصیفگر. هر یک بر اساس شبکه های عصبی کانولوشنال (CNN) و با الگوبرداری از شبکه های اخیر [6، 9، 10] که نشان داده شده عملکردهای فردی را به خوبی انجام می دهند, هستند. برای ترکیب آنها از ترانسفورماتورهای مکانی [11] برای تصحیح پچ های تصویر با توجه به خروجی آشکارساز و برآوردگر جهت استفاده می کنیم. ما همچنین رویکردهای سنتی برای حذف حداکثر غیرمحلی (NMS) را با تابع argmax نرم جایگزین میکنیم [12]. این به ما امکان میدهد که تمایز انتها به انتها را حفظ کرده و منجر به ایجاد یک شبکه کامل میشود که هنوز هم میتوان باbackpropagation آن را آموزش داد، که در مورد هیچ معماری دیگری که ما میشناسیم صدق نمیکند.
همچنین، ما نشان می دهیم که چگونه می توان چنین خط لوله ای را به شیوه ای موثر یاد گرفت. برای این منظور، ما یک شبکه سیامی میسازیم و با استفاده از نقاط کلیدی تولید شده توسط الگوریتم ساختار از حرکت (SfM) که روی تصاویر صحنهای گرفته شده تحت دیدگاهها و شرایط نوری مختلف اجرا میکنیم، آن را آموزش میدهیم تا وزن آن را یاد بگیریم. ما این مسئله آموزشی را بر روی پچهای تصویر استخراج شده در مقیاس های مختلف فرموله می کنیم تا بهینه سازی قابل انجام باشد.
در عمل، متوجه شدیدم آموزش کامل معماری از ابتدا غیرممکن است، زیرا اجزای جداگانه سعی میکنند برای اهداف مختلف بهینهسازی شوند. در عوض، ما یک رویکرد یادگیری خاص برای غلبه بر این مشکل را معرفی می کنیم. این راه حل شامل این است که اول توصیفگر و بعد براوردگر جهت آموزش ببیند و در آخربراساس توصیفگرو براوردگر جهت آموزش داده شده برای آشکارساز استفاده شود. که در کل شبکه متمایز می شود. در زمان آزمایش، آشکارساز را که روی کل تصویر در فضای مقیاس اجرا می شود، از برآوردگر جهت و توصیفگر جدا می کنیم که فقط نقاط کلیدی را پردازش می کنند.
روش
در این بخش، ابتدا کل خط لوله تشخیص و توصیف ویژگی را بر اساس معماری سیامی که در شکل 2 نشان داده شده است، فرموله می کنیم. سپس، نوع داده ای را که برای آموزش شبکه های خود نیاز داریم و نحوه جمع آوری آن ها مورد بحث قرار می دهیم. سپس روند آموزش را به تفصیل شرح می دهیم.
3.1 فرمول مسئله
ما به جای تصاویر کامل، از پچ های تصویری به عنوان ورودی استفاده می کنیم. این باعث می شود که یادگیری مقیاس پذیر بدون از دست دادن اطلاعات باشد، زیرا اکثر مناطق تصویر حاوی نقاط کلیدی نیستند. پچ ها از نقاط کلیدی استفاده شده توسط خط لوله SfM استخراج می شوند، همانطور که در بخش 3.2 مورد بحث قرار خواهد گرفت. ما آنها را به اندازهای کوچک در نظر میگیریم که میتوانیم فرض کنیم فقط یک ویژگی محلی غالب در مقیاس داده شده دارند، که فرآیند یادگیری را به یافتن متمایزترین نقطه در پچ کاهش میدهد.
برای آموزش شبکه خود، معماری سیامی چهار شاخه ای را ایجاد می کنیم که در شکل 2 تصویر شده است. هر شاخه شامل سه CNN مجزا، یک آشکارساز، یک برآوردگر جهت و یک توصیفگر است. برای اهداف آموزشی، ما از پچ چهارتایی تصویر استفاده می کنیم. هر کدام شامل دو پچ تصویری P1 و P2 است که مربوط به نماهای متفاوت از یک نقطه سه بعدی است، یک پچ تصویری P3 که حاوی نگاشت نقطه سه بعدی متفاوت است و یک پچ تصویری P4 که حاوی هیچ نقطه کلیدی نیست. در طول آموزش، i-امین پچ Pi هر چهارپچ از شاخه i-ام عبور می کند.
برای دستیابی به تمایز انتها به انتها، اجزای هر شاخه به صورت زیر به هم متصل می شوند:
- با توجه به یک پچ از تصویر ورودی P، آشکارساز یک نقشه امتیاز S ارائه می دهد.
- یک soft argmax [12] را روی نقشه امتیاز S انجام می دهیم و مکان x یک نقطه ویژگی بالقوه را برمی گردانیم.
- ما یک پچ کوچکتر p با مرکز x را با لایه Crop Spatial Transformer استخراج می کنیم (شکل 2). این به عنوان ورودی برآوردگر جهت عمل می کند.
- تخمینگر جهت یک جهت با نام θ را برای پچ پیش بینی می کند.
- ما p را مطابق این جهت با استفاده از دومین لایه ترانسفورماتور مکانی، که در شکل 2 با عنوان Rot مشخص شده است، می چرخانیم تا pθ تولید شود.
- pθ به شبکه توصیفگر وارد می شود که بردار ویژگی d را محاسبه می کند.
توجه داشته باشید که لایههای Spatial Transformer تنها برای دستکاری پچ های تصویر و حفظ تفاوتپذیری استفاده میشوند. آنها ماژول های آموخته شده نیستند. همچنین، هم مکان x پیشنهاد شده توسط آشکارساز و هم جهت θ پیشنهادی برای پچ به طور ضمنی در نظر گرفته میشوند، به این معنی که به کل شبکه اجازه میدهیم مکانهای متمایز و جهتگیریهای پایدار را در حین یادگیری کشف کند.
از آنجایی که شبکه ما از اجزایی با اهداف مختلف تشکیل شده است، یادگیری وزن ها امری بی اهمیت نیست. تلاش های اولیه ما برای آموزش شبکه به طور کلی از ابتدا ناموفق بود. بنابراین ما یک رویکرد یادگیری ویژه مسئله را طراحی کردیم که شامل یادگیری ابتدا توصیفگر، سپس برآوردگر جهت با توجه به توصیفگر آموخته شده، و در نهایت آشکارساز، مشروط به دو مورد دیگر است. این به ما امکان میدهد تا تخمینگر جهت را برای توصیفگر و آشکارساز را برای دو جزء دیگر تنظیم کنیم.
مجموعه داده هایی وجود دارند که می توانند برای آموزش توصیفگرهای ویژگی [24] و برآوردگرهای جهت [9] استفاده شوند. با این حال، نحوه آموزش یک آشکارساز نقطه کلید چندان روشن نیست، و اکثریت قریب به اتفاق تکنیکها هنوز بر ویژگیهای دست ساز متکی هستند.آشکارساز TILDE [6] یک استثنا است، اما مجموعه داده آموزشی هیچ تغییر دیدگاهی را نشان نمی دهد
برای دستیابی به تغییر ناپذیری، ما به تصاویری نیاز داریم که نماهایی از یک صحنه را تحت شرایط نوری متفاوت و از منظرهای مختلف مشاهده کنند.
بنابراینما به مجموعه های تصویر گردشگری عکاسی روی آوردیم. ما از مجموعههای سیرک پیکادلی در لندن و فروم رومی در رم از [29] برای بازسازی سه بعدی با استفاده از VisualSFM [30] که متکی به ویژگیهای SIFT است، استفاده کردیم. Piccadilly شامل 3384 تصویر است و بازسازی دارای 59 هزار نقطه منحصر به فرد با میانگین 6.5 مشاهده برای هر یک است. Roman-Forum شامل 1658 تصویر و 51 هزار نقطه منحصر به فرد است که به طور میانگین برای هر کدام 5.2 مشاهده شده است. شکل 3 چند نمونه را نشان می دهد
ما دادهها را به مجموعههای آموزشی و اعتبارسنجی تقسیم میکنیم، دیدگاههای نقاط آموزشی در مجموعه اعتبارسنجی را کنار میگذاریم و بالعکس. برای ساختن نمونههای آموزشی مثبت، ما فقط ویژگیهایی را در نظر میگیریم که از فرآیند بازسازی SfM جان سالم به در میبرند. برای استخراج پچ هایی که حاوی هیچ نقطه کلیدی نیستند، همانطور که در روش آموزشی ما لازم است، بهطور تصادفی از مناطق تصویری که فاقد ویژگی SIFT هستند، از جمله مناطقی که توسط SfM استفاده نشدهاند، نمونهبرداری میکنیم.
ما پچ های آموزشی خاکستری را با توجه به مقیاس σ نقطه، برای نواحی از تصویر که دارای نقطه کلیدی وبدون نقطه کلیدی استخراج می کنیم. پچ های P از یک ناحیه پشتیبانی 24σ × 24σ در این نواحی استخراج میشوند و به پیکسلهای S×S استاندارد میشوند که در آن S = 128 است.
پچ های کوچکتر p و pθ که به عنوان ورودی برای برآوردگر جهت و توصیفگر عمل می کنند، نسخه های برش خورده و چرخانده شده از این پچ ها هستند که هر کدام دارای اندازه s×s هستند که در آن s = 64 است. وصله های کوچکتر به طور موثر با منطقه پشتیبانی توصیفگر SIFT با سایز 12σمطابقت دارند. . برای جلوگیری از سوگیری داده ها، اعوجاجات تصادفی یکنواخت را در محل وصله با دامنه 20٪ (4.8σ) اعمال می کنیم. در نهایت، تکهها را با میانگین مقیاس خاکستری و انحراف معیار کل مجموعه آموزشی نرمال میکنیم.
توصیفگر
یادگیری توصیفگرهای ویژگی از وصلههای تصویر خام در طول سال گذشته به طور گسترده مورد تحقیق قرار گرفته است [7، 8، 10، 27، 28، 31]، با چندین گزارش کار نتایج چشمگیر در مورد بازیابی پچ، استریو خط پایه باریک، و تطبیق شکلهای غیر فرمی. در اینجا ما به شبکههای نسبتاً ساده [10]، با سه لایه کانولوشن با واحدهای تانژانت هیپربولیک، ادغام l2 [32] و نرمالسازی تفریق محلی، تکیه میکنیم، زیرا نیازی به یادگیری متریک ندارند. توصیفگر را می توان به سادگی به صورت فرمول درآورد. توصیفگر را می توان به سادگی به صورت رسمی درآورد
d = hρ(pθ)
که در آن (.)h نشان دهنده توصیفگرCNN,
ρ پارامترهای آن
pθ وصله چرخش یافته از برآوردگر جهت است
هنگام آموزش توصیفگر، ما هنوز آشکارساز و برآوردگر جهت را آموزش نداده ایم. بنابراین ما از مکان و جهت نقاط کلیدی استفاده شده توسط SfM برای تولید پچ های تصویر pθ استفاده میکنیم.
ما توصیفگر را با به حداقل رساندن مجموع ضرر برای جفت پچ های مرتبط(pθ1,pθ2) و غیر مرتبط (pθ1,pθ3) آموزش می دهیم.
تابع هزینه به عنوان hinge embedding فاصله اقلیدسی بین بردارهای توصیف آنها تعریف می شود. ما نوشتیم
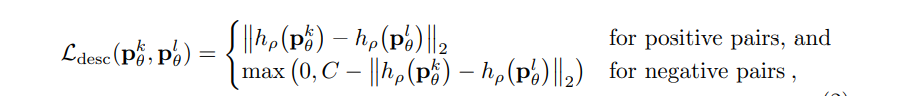
که در آن نمونههای مثبت و منفی جفتپچ ها هستند که با نقاط سه بعدی فیزیکی مشابهی مطابقت دارند یا ندارند،||·|| فاصله اقلیدسی است و C = 4 حاشیه برای جاسازی است.
ما از استخراج سخت در طول آموزش استفاده می کنیم که همان طور که در [10] نشان داده شده برای عملکرد توصیفگر حیاتی است. با پیروی از این روش، نمونه جفتهای Kf را فوروارد میکنیم و فقط از جفتهای Kb با بیشترین ضرر آموزش برای back-propagation استفاده میکنیم، جایی که r = Kf /Kb ≥ 1 «نسبت استخراج» است.
در [10] شبکه بدون ماینینگ از قبل آموزش داده شد و سپس با r = 8 تنظیم دقیق شد. در اینجا، ما از یک طرح استخراج افزایشی استفاده می کنیم که در آن با r = 1 شروع می کنیم و نسبت ماینینگ را در هر 5000 دسته دو برابر می کنیم. ما از دسته های متعادل با 128 جفت مثبت و 128 جفت منفی استفاده می کنیم که هر کدام را جداگانه استخراج می کنیم.
برآوردگر جهت
برآوردگر جهت ما از [9] الهام گرفته است. با این حال، این مورد خاص به پیش محاسباتی بردارهای توصیف برای جهت های چندگانه برای محاسبه عددی Jacobian پارامترهای روش با توجه به جهت نیاز دارد. این یک محدودیت مهم برای ما است زیرا ما خروجی آشکارساز را به طور ضمنی در سراسر خط لوله بررسی می کنیم و بنابراین محاسبه بردارهای توصیف از قبل ممکن نیست.بنابراین پیشنهاد می کنیم به جای آن از ترانسفورماتورهای مکانی [11] برای یادگیری جهت استفاده کنیم. با توجه به یک پچ p از ناحیه پیشنهادی آشکارساز، برآوردگر جهت یک جهت را پیش بینی می کند.
θ = gφ(p)
که در آن g نشانگر برآوردگر جهت CNN و φ پارامترهای آن است. همراه با مکان x از آشکارساز و P پچ اصلی تصویر ، θ توسط دومین لایه ترانسفورماتور مکانی Rot(.) برای ارائه یک پچ pθ = Rot (P, x, θ) استفاده میشود که نسخه چرخانده شده p است.
ما برآوردگر جهت را آموزش می دهیم تا جهت هایی را ارائه دهد که فاصله بین بردارهای توصیف را برای نماهای مختلف نقاط سه بعدی یکسان به حداقل برساند. ما از توصیفگر آموزش دیده برای محاسبه بردارهای توصیف استفاده می کنیم و از آنجایی که آشکارساز هنوز آموزش داده نشده است، از مکان های تصویر از SfM استفاده می کنیم. به طور فرمولی، ما هزینه را برای جفت پچ های مرتبط، که به عنوان فاصله اقلیدسی بین بردارهای توصیف آنها تعریف می شود، به حداقل می رسانیم.
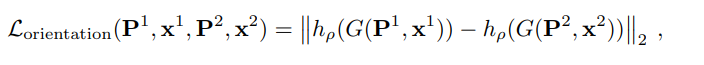
آشکارساز
آشکارساز یک پچ تصویر را به عنوان ورودی می گیرد و یک نقشه امتیاز را برمی گرداند. ما آن را به عنوان یک لایه کانولوشن و به دنبال آن توابع فعال سازی خطی piecewise مانند TILDE [6] پیاده سازی می کنیم. به طور دقیق تر، نقشه امتیاز S برای پچ P به صورت زیر محاسبه می شود:
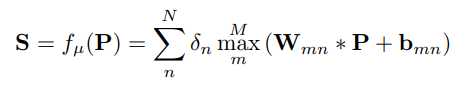
در جایی که fµ(P) خود آشکارساز را با پارامترهای µ نشان میدهد، δn +1 است اگر n فرد باشد و -1 در غیر این صورت، μ از فیلترهای Wmn ساخته شده است و bmn بایاس لایه کانولوشن برای یادگیری ، ∗ نشاندهنده عملیات کانولوشن است، و N و M فراپارامترهایی هستند که پیچیدگی تابع فعال سازی خطی تکه ای را کنترل می کنند. تفاوت اصلی با TILDE در نحوه آموزش این لایه نهفته است.برای اینکه اجازه دهیم S در مکانهایی غیر از یک مکان ثابت بازیابی شده توسط SfM، ماکزیمم داشته باشد، این مکان را بهطور ضمنی، بهعنوان یک متغیر پنهان در نظر میگیریم. روش ما به طور بالقوه می تواند نکاتی را کشف کند که قابل اطمینان تر و یادگیری آسان تر هستند، در حالی که [6] نمی تواند. اتفاقاً، در آزمایشهای اولیهمان، متوجه شدیم که مجبور کردن آشکارساز برای بهینهسازی مستقیم برای مکانهای SfM مضر است.

همانطور که Orientation Estimator و Descriptor در این مرحله آموخته شده اند، می توانیم آشکارساز را با توجه به خط لوله کامل آموزش دهیم. برای بهینه سازی پارامترهای μ، ما فاصله بین بردارهای توصیف را برای جفت تکههایی که با نقاط فیزیکی یکسان مطابقت دارند، به حداقل میرسانیم، در حالی که امتیاز طبقهبندی را برای تکههایی که با همان نقاط فیزیکی مطابقت ندارند، به حداکثر میرسانیم.
دقیق تر، با توجه به آموزش چهارتایی (p1,p2,p3,p4) جایی که p1,p2 مرتبط با نقاط فیزیکی یکسان و p1,p3 مربوط با نقاط ویژگی متقاوت sfm و p4 یک نقطه غیر ویژگی . ما جمع تابع هزینه را حداقل می کنیم.

توجه داشته باشید که مکان نقاط کلیدی x فقط به طور ضمنی ظاهر می شود و در طول آموزش کشف می شود. علاوه بر این، هر سه جزء با یادگیری آشکارساز گره خورده اند. همانند توصیفگر، ما از یک استراتژی استخراج سخت استفاده می کنیم، در این مورد با نسبت استخراج ثابت r = 4.
در عمل، از آنجایی که توصیفگر قبلاً مقداری مقاوم را یاد میگیرد، یافتن نکات جدید برای یادگیری به طور ضمنی برای آشکارساز دشوار است. برای اینکه آشکارساز با ایده ای از مناطقی که باید پیدا کند شروع کند، ابتدا پچ های پیشنهادی p = Crop(P, softargmax(fµ(P))) را که با همان نقاط فیزیکی مطابقت دارند، محدود می کنیم تا همپوشانی داشته باشند. سپس آموزش آشکارساز را بدون این محدودیت ادامه می دهیم.
به طور خاص، هنگام پیشآموزش آشکارساز، Lpair را در معادله 8 جایگزین میکنیم. با جفت L˜، که در آن جفت L˜ برابر با 0 است که پچهای پیشنهادی دقیقاً همپوشانی دارند، و در غیر این صورت با فاصله بین آنها افزایش مییابد. بنابراین ما می نویسیم
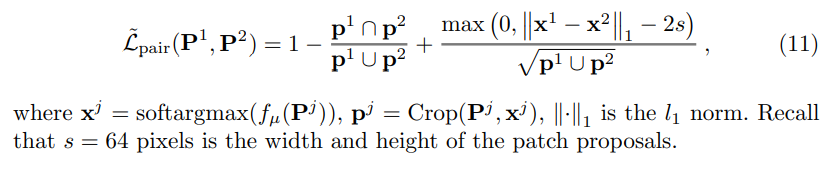
خط لوله زمان اجرا
خط لوله مورد استفاده در زمان اجرا در شکل 4 نشان داده شده است. از آنجایی که روش ما بر روی وصله ها آموزش داده شده است، به سادگی اعمال آن روی کل تصویر نیاز به آزمایش شبکه با یک طرح پنجره کشویی روی کل تصویر دارد. در عمل، این بسیار پر هزینه خواهد بود. خوشبختانه، از آنجایی که برآوردگر جهت و توصیفگر فقط باید در ماکزیممهای محلی اجرا شوند، میتوانیم به سادگی آشکارساز را از بقیه جدا کنیم تا آن را روی تصویر کامل اعمال کنیم و تابع softargmax را با NMS جایگزین کنیم، همانطور که در شکل قرمز مشخص شده است. 4. سپس Orientation Estimator و Descriptor را فقط برای وصله هایی که در مرکز حداکثر محلی قرار دارند اعمال می کنیم.
دقیق تر، ما آشکارساز را به طور مستقل بر روی تصویر در وضوح های مختلف اعمال می کنیم تا نقشه های امتیاز را در فضای مقیاس به دست آوریم. سپس یک طرح NMS سنتی شبیه به [1] برای شناسایی مکانهای نقطه ویژگی اعمال میکنیم.
اعتبار سنجی تجربی
در این بخش ابتدا مجموعه داده ها و معیارهایی را که استفاده کرده ایم ارائه می کنیم. سپس نتایج کیفی را ارائه میکنیم، و به دنبال آن یک مقایسه کامل در برابر تعدادی از کارهای گذشته، که ما به طور مداوم از آنها بهتر عمل میکنیم، ارائه میکنیم. در نهایت، برای درک بهتر اینکه چه عناصری از رویکرد ما بیشتر به این نتیجه کمک میکنند، اهمیت پیشآموزش جزء آشکارساز را که در بخش 3.5 مورد بحث قرار گرفت، مطالعه میکنیم و دستاوردهای عملکرد قابل انتساب به هر جزء را تجزیه و تحلیل میکنیم.
مجموعه داده و تنطیمات آزمایش
ما خط لوله خود را بر اساس سه مجموعه داده استاندارد ارزیابی می کنیم:
- مجموعه داده Strecha [33]، که شامل 19 تصویر از دو صحنه است که از دیدگاههای به طور فزایندهای متفاوت دیده میشوند.
- مجموعه داده DTU [34]، که شامل 60 دنباله از اشیا با دیدگاه ها و تنظیمات روشنایی مختلف است. ما از این مجموعه داده برای ارزیابی روش خود تحت تغییرات دیدگاه استفاده می کنیم.
- مجموعه داده وبکم [6] که شامل 710 تصویر از 6 صحنه با تغییرات روشنایی قوی است اما از یک دیدگاه دیده میشود. ما از این مجموعه داده برای ارزیابی روش خود تحت تغییرات نور طبیعی استفاده می کنیم
برای Strecha و DTU از ground truth ارائه شده برای ایجاد مطابقات بین دیدگاه ها استفاده می کنیم. ما حداکثر از 1000 نقطه کلیدی در هر تصویر استفاده می کنیم و از پروتکل ارزیابی استاندارد [35] در ناحیه دیدگاه مشترک پیروی می کنیم. این به ما امکان می دهد معیارهای زیر را ارزیابی کنیم.
تکرارپذیری (Rep.): تکرارپذیری نقاط مشخصه که به صورت یک نسبت بیان می شود. این متریک عملکرد آشکارساز نقطه ویژگی را با گزارش نسبت نقاط کلیدی که به طور مداوم در منطقه مشترک یافت می شود، ثبت می کند.
- نزدیکترین همسایه میانگین دقت متوسط (NN mAP): ناحیه زیر منحنی (AUC) منحنی دقت-یادآوری، با استفاده از استراتژی تطبیق نزدیکترین همسایه. این متریک میزان تمایز توصیفگر را با ارزیابی آن در آستانه های فاصله چندگانه توصیفگر نشان می دهد.
- امتیاز منطبق (M. Score): نسبت تناظرهای ground truth که می تواند توسط کل خط لوله بازیابی شود به تعداد ویژگی های پیشنهاد شده توسط خط لوله در منطقه دیدگاه مشترک. این متریک عملکرد کلی خط لوله را اندازه گیری می کند.