
شبکه عمیق Super Point
آگوست 15, 2022شبکه عصبی نگاشت خودسازمانده
آگوست 26, 2022توضیح مختصر شبکه تطبیق تصویر super point

سلام خوانندگان!! شاید قبلاً در مورد نقاط کلیدی در حوزه بینایی رایانه شنیده باشید. دو نوع نقطه کلیدی در بینایی کامپیوتر رایج است:
- نقاط کلیدی معنایی نقاط مورد علاقه با معنای معنایی برای اشیاء موجود در یک تصویر، مانند گوشه چشم چپ صورت، شانه راست یک فرد یا توپی لاستیک جلو سمت چپ یک خودرو هستند.
- نقاط کلیدی، نقاط سطح پایین تری هستند که ممکن است معنای معنایی واضحی نداشته باشند، مانند نقطه گوشه یا نقطه پایان یک پاره خط.

از آنجایی که نقاط کلیدی از نظر معنایی بد تعریف شده اند و بنابراین یک حاشیه نویس انسانی نمی تواند به طور قابل اعتماد و مکرر مجموعه ای از نقاط مورد علاقه را شناسایی کند.
بنابراین غیرممکن است که وظیفه تشخیص نقطه علاقه را به عنوان یک مسئله یادگیری نظارت شده فرموله کنیم.
کاربردهای سوپرپوینت:
- تشخیص ویژگی
- تشخیص ژست
- ردیابی اشیا
- تشخیص بیرونی
- تشخیص اثر انگشت
- رباتیک و واقعیت افزوده
بیایید کمی در مورد نقاط علاقه یاد بگیریم:
نقاط مورد علاقه، مکانهای دوبعدی در یک تصویر هستند که در شرایط نوری و دیدگاههای مختلف پایدار و قابل تکرار هستند.
به جای استفاده از نظارت انسانی برای تعریف نقاط کلیدی در تصاویر واقعی، SuperPoint راه حلی با نظارت شخصی با استفاده از خودآموزی ارائه می دهد.
این کار از طریق ایجاد یک مجموعه داده بزرگ از مکانهای نقاط کلیدی واقعی گراند تورث در تصاویر واقعی با استفاده از یک آشکارساز پایه به نام Magic Point انجام میشود.
آموزش سوپرپوینت شامل چندین مرحله است:
- پیش آموزش نقطه کلیدی
- خود برچسب گذاری نقطه کلیدی
- آموزش مشترک
بیایید این مراحل را با جزئیات بررسی کنیم
پیش آموزش نقطه کلیدی
ما ابتدا مجموعه داده مصنوعی را تولید می کنیم که شامل اشکال هندسی ساده مانند ستاره های خطوط مکعبی و تخته شطرنجی با استفاده از کد ساده پایتون است.
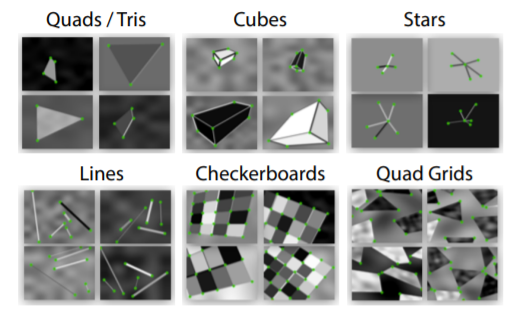
در این تولید داده، تصاویر شکل هندسی را همراه با برچسب ها ایجاد می کنیم. با استفاده از این مجموعه داده، آشکارساز پایه را که MagicPoint نامیده می شود، آموزش خواهیم داد.
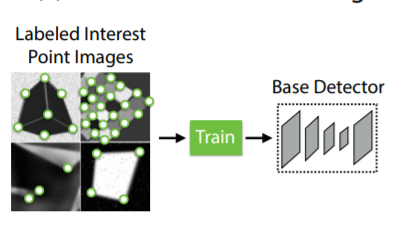
برای ایجاد نقاط کلیدی حقیقی گراند تورث، ابتدا یک شبکه عصبی کاملاً کانولوشنال را بر روی میلیونها نمونه از مجموعه داده مصنوعی که ایجاد کردیم به نام اشکال مصنوعی آموزش میدهیم.
MagicPoint در اشکال مصنوعی به خوبی عمل می کند، اما در مقایسه با آشکارسازهای نقطه کلیدی کلاسیک در مجموعه متنوعی از بافت ها و الگوهای تصویر، روی تصاویر واقعی خیلی خوب تعمیم نمی یابد.
MagicPoint بسیاری از مکانهای بالقوه مورد علاقه را از دست میدهد.
برای پر کردن این شکاف در عملکرد روی تصاویر واقعی، یک تکنیک چند مقیاسی و چند تبدیلی به نام تطبیق هوموگرافیک توسعه داده شد.
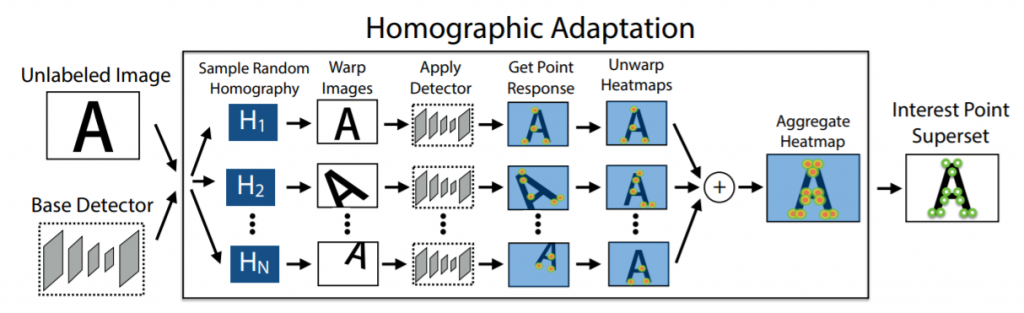
تطبیق هوموگرافیک همراه با آشکارساز MagicPoint برای افزایش عملکرد آشکارساز و ایجاد نقاط کلیدی گراند تورث ساختگی استفاده می شود.
تطبیق هوموگرافیک برای فعال کردن آموزش خود نظارت آشکارسازهای نقطه کلیدی طراحی شده است
در این فرآیند، تصویر ورودی را چندین بار با استفاده از هموگرافی تصادفی چرخش میدهیم و از آشکارساز magic point استفاده میکنیم تا نقاط کلیدی روی تصویرچرخش خورده را بدست آوریم.
هنگامی که نقاط کلیدی روی تصویرچرخش خورده را داشته باشیم، نقاط کلیدی را بدون چرخش می کنیم، به این ترتیب نقاط تصویر اصلی را دردیدگاه و مقیاس های مختلف بدست می آوریم.
خود برچسب گذاری نقطه کلیدی
هنگامی که مدل آموزش دیده MagicPoint را داشته باشیم، از این مدل برای ایجاد نقاط کلیدی گراند تورث ساختگی استفاده خواهیم کرد. در اینجا ما از فرآیند تطبیق هوموگرافیک همانطور که قبلاً صحبت کردیم استفاده خواهیم کرد.
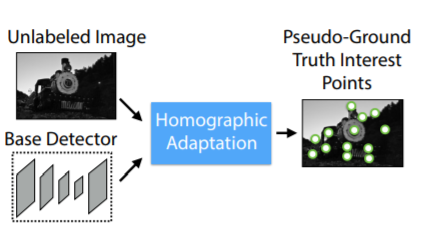
همانطور که در اینجا بحث کردیم، نقاط کلیدی گراند تورث ساختگی را برای MSCOCO 2014 ایجاد خواهیم کرد.
این مجموعه داده تولید شده برای آموزش Magic Point استفاده خواهد شد.
ما این فرآیند را چندین بار انجام خواهیم داد.
معماری سوپرپوینت
معماری SuperPoint از یک رمزگذار به سبک VGG برای کاهش ابعاد تصویر استفاده می کند.
رمزگذار از لایههای کانولوشن، سمپلینگ مکانی از طریق پولینگ و توابع فعالسازی غیرخطی تشکیل شده است.
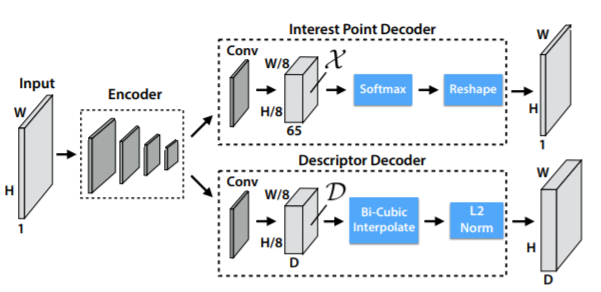
رمزگذار
این معماری دارای هشت لایه کانولوشن 3×3 با اندازههای 64–64–64–64–128–128– 128–128 است. برای هر دو لایه تبدیل، یک لایه max pool 2×2 وجود دارد.
تمام لایههای کانولوشن در شبکه با فعالسازی غیرخطی ReLU و نرمال سازی BatchNorm دنبال میشوند.
رمزگشای توصیفگر
سر توصیفگر D∈ Hc×Wc×D را محاسبه می کند و یک تانسور اندازه H×W×D را خروجی می دهد.
سپس رمزگشا tf.image.resize_bilinear از توصیفگر را انجام می دهد و سپس L2-normalize (tf.nn.l2_normalize) فعال سازی ها را به طول واحد انجام می دهد.
آموزش مشترک
آموزش مشترک آموزش سوپر پوینت با استفاده از مجموعه داده coco است.
آموزش مشترک بر روی 2 تصویر انجام می شود که با هموگرافی H به طور تصادفی ایجاد شده مرتبط هستند. این فرآیند آموزشی به ما امکان می دهد تا دو تابع هدف را به طور همزمان بهینه کنیم.
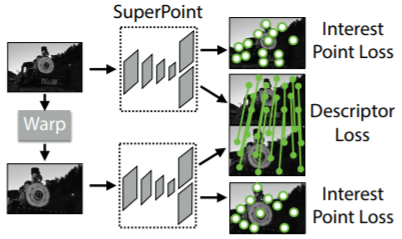
بسیاری از پارامترهای شبکه بین دو وظیفه مشترک هستند، متفاوت از سیستمهای سنتی که ابتدا نقاط کلیدی را شناسایی میکنند، سپس توصیفگرها را محاسبه میکنند و توانایی اشتراکگذاری محاسبات و نمایش در بین دو وظیفه را ندارند.
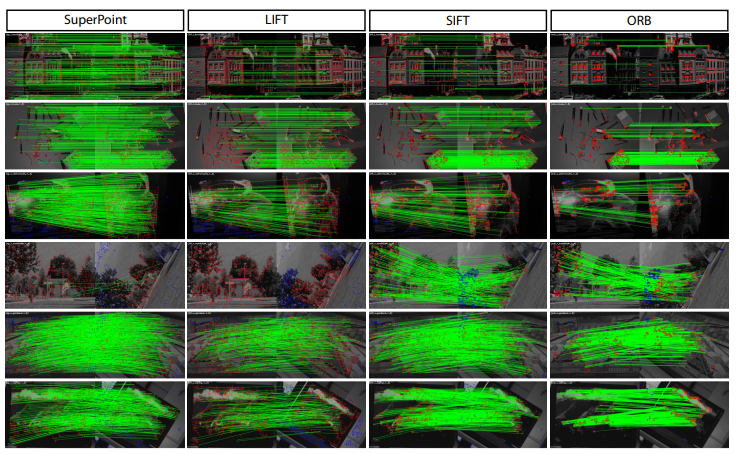
نتایج
خطوط سبز مطابقت صحیح را نشان می دهد. SuperPoint در مقایسه با LIFT، SIFT و ORB تمایل به تولید منطبقات متراکم و صحیح تری دارد. در حالی که ORB بالاترین میانگین تکرارپذیری را دارد،آشکارسازی ها در کنار هم قرار می گیرند و به طور کلی به تطابق بیشتر یا تخمین های هموگرافی دقیق تر منجر نمی شوند.