
بینایی ماشین با پایتورچ
آگوست 24, 2023استفاده از شبکه عصبی کانولوشنال برای طبقه بندی ارقام دست نویس در پایتورچ
آگوست 25, 2023آموزش یک شبکه عصبی متراکم ساده بینایی ماشین برای تشخیص اعداد دست نویس در پایتورچ
بیایید روی مسئله تشخیص رقم دست نویس تمرکز کنیم. این یک مسئله طبقه بندی است، زیرا برای هر تصویر ورودی باید کلاس آن را مشخص کنیم ; یعنی هر تصویر ورودی, نماینگر کدام رقم است؟!
در این قسمت، ما با سادهترین رویکرد ممکن برای طبقهبندی تصویر یعنی یک شبکه عصبی کاملاً متصل (که پرسپترون نیز نامیده میشود) شروع میکنیم. نحوه تعریف شبکههای عصبی در PyTorch و نحوه عملکرد الگوریتم آموزش را مرور میکنیم. ( اگر با این مفاهیم آشنا هستید – به بخش بعدی بروید، جایی که ما شبکه های عصبی کانولوشنال (CNN) را معرفی می کنیم.)
ما از «pytorchcv» برای بارگذاری تمام داده هایی که در نوشته قبلی در مورد آنها صحبت کردیم استفاده می کنیم.( قبل از اجرای کدهای اصلی, محتویات لینک زیر را دانلود یا کپی کنید و در محیط ide تون اجرا بگیرید.)
!wget https://raw.githubusercontent.com/MicrosoftDocs/pytorchfundamentals/main/computer-vision-pytorch/pytorchcv.py
import torch
import torch.nn as nn
import torchvision
import matplotlib.pyplot as plt
from torchinfo import summary
from pytorchcv import load_mnist, plot_results
load_mnist()
شبکه های عصبی متراکم کاملاً متصل
یک شبکه عصبی پایه در PyTorch از تعدادی لایه تشکیل شده است. ساده ترین شبکه فقط شامل یک لایه کاملاً متصل است که لایه خطی نامیده می شود، در این مثال این لایه 784 ورودی (یک ورودی برای هر پیکسل تصویر ورودی) و 10 خروجی (یک خروجی برای هر کلاس)دارد. همانطور که در نوشته قبلی بیان کردیم، ابعاد تصاویر ارقام ما 1×28×28 است، یعنی هر تصویر حاوی 28×28=784 پیکسل مختلف است.
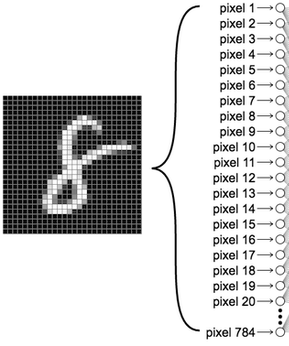
از آنجایی که لایه خطی انتظار دارد ورودیش به عنوان بردار یک بعدی باشد، باید لایه دیگری به نام Flatten را (که مثل پلی دو بعد را به یک بعد تبدیل می کند) در شبکه وارد کنیم تا شکل تانسور ورودی را از 1×28×28 به 784 تغییر دهیم. پس از Flatten، یک لایه خطی اصلی وجود دارد (به نام متراکم در اصطلاح PyTorch) که 784 ورودی را به 10 خروجی تبدیل می کند یعنی برای هر کلاس یک خروجی. ما می خواهیم n-امین خروجی شبکه احتمال برابری رقم ورودی با n را برگرداند.
از آنجا که خروجی یک لایه کاملاً متصل بین 0 و 1 نرمال سازی نشده است، نمی توان آن را به عنوان احتمال در نظر گرفت. علاوه بر این، اگر میخواهید خروجیها، احتمالات ارقام مختلف باشند، جمع همه آنها باید 1 شوند. برای تبدیل بردار خروجی به بردار احتمال، تابعی به نام Softmax اغلب به عنوان آخرین تابع فعالسازی در یک شبکه عصبی طبقهبندی استفاده میشود. به عنوان مثال، softmax([−1,1,2])=[0.035,0.25,0.705].
در PyTorch، ما اغلب ترجیح می دهیم از تابع LogSoftmax استفاده کنیم، که لگاریتم احتمالات خروجی را نیز محاسبه می کند. برای تبدیل بردار خروجی به احتمالات واقعی، باید torch.exp را از خروجی بگیریم.
بنابراین، معماری شبکه را می توان با دنباله ای از لایه های به شکل زیرنشان داد:
می توان آن را در PyTorch به روش زیر با استفاده از دستور ترتیبی تعریف کرد:
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784,10), # 784 inputs, 10 outputs
nn.LogSoftmax())
این دنباله از لایه ها در زیر با جزئیات بیشتر نشان داده شده است. برای همه بردارها در این نمودار اندازه تانسور را نیز نشان می دهیم.
در سمت راست این نمودار، خروجی مورد انتظارشبکه را نیز داریم که به صورت بردار “یکی فعال” کدگذاری شده , نشان داده شده است. خروجی مورد انتظار با خروجی واقعی شبکه ما با استفاده از تابع ضرر مقایسه می شود که یک عدد – ضرر – را به عنوان خروجی می دهد. هدف ما در طول آموزش شبکه این است که با تنظیم پارامترهای مدل یعنی وزن لایه ها، این تلفات را به حداقل برسانیم.
آموزش شبکه
شبکه ای که به این روش تعریف می شود می تواند هر رقمی را به عنوان ورودی بگیرد و بردار احتمالات را به عنوان خروجی تولید کند. بیایید ببینیم این شبکه با دادن یک رقم از مجموعه داده ما چگونه عمل می کند:
print('Digit to be predicted: ',data_train[0][1])
torch.exp(net(data_train[0][0]))
Digit to be predicted: 5
C:\winapp\Miniconda3\envs\py38\lib\site-packages\torch\nn\modules\container.py:119: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument.
input = module(input)
tensor([[0.1174, 0.1727, 0.0804, 0.1333, 0.0790, 0.0902, 0.0657, 0.0871, 0.0807,
0.0933]], grad_fn=<ExpBackward>)
از آنجا که ما از LogSoftmax به عنوان فعال سازی نهایی شبکه خود استفاده می کنیم، خروجی شبکه را از torch.exp برای بدست آوردن احتمالات عبور می دهیم.
همانطور که می بینید شبکه احتمالات مشابهی را برای هر رقم پیش بینی می کند. این به این دلیل است که در مورد نحوه تشخیص ارقام آموزش ندیده است. ما باید داده های آموزشی خود را به آن بدهیم تا شبکه را در مجموعه داده های خود آموزش دهیم.
برای آموزش مدل باید دسته هایی از مجموعه داده هایمان با اندازه معین ایجاد کنیم، مثلاً 64. PyTorch یک شی به نام DataLoader دارد که می تواند دسته هایی از داده های ما را به طور خودکار برای ما ایجاد کند:
train_loader = torch.utils.data.DataLoader(data_train,batch_size=64)
test_loader = torch.utils.data.DataLoader(data_test,batch_size=64) # we can use larger batch size for testing
مراحل فرآیند آموزش به شرح زیر است:
ما یک minibatch از مجموعه داده ورودی می گیریم که شامل داده های ورودی (ویژگی ها) و نتیجه مورد انتظار (برچسب) است.
ما نتیجه پیش بینی شده را برای این مینی بچ محاسبه می کنیم.
تفاوت بین این نتیجه و نتیجه مورد انتظار با استفاده از یک تابع خاص به نام تابع ضرر محاسبه می شود. تابع Loss نشان می دهد که خروجی شبکه چقدر با خروجی مورد انتظار متفاوت است. هدف از آموزش ما به حداقل رساندن ضرر است.
ما گرادیان های این تابع تلفات را با توجه به وزن مدل (پارامترها) محاسبه می کنیم، و سپس با تنظیم وزن ها برای بهینه سازی عملکرد شبکه استفاده می کنیم. میزان تنظیم توسط پارامتری به نام نرخ یادگیری کنترل می شود و جزئیات الگوریتم بهینه سازی در شی بهینه ساز تعریف می شود.
ما آن مراحل را تکرار می کنیم تا کل مجموعه داده پردازش شود. (یک گذر کامل از مجموعه داده، دوره نامیده می شود.)
در اینجا یک تابع است که آموزش یک دوره را انجام می دهد:
def train_epoch(net,dataloader,lr=0.01,optimizer=None,loss_fn = nn.NLLLoss()):
optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)
net.train()
total_loss,acc,count = 0,0,0
for features,labels in dataloader:
optimizer.zero_grad()
out = net(features)
loss = loss_fn(out,labels) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
total_loss+=loss
_,predicted = torch.max(out,1)
acc+=(predicted==labels).sum()
count+=len(labels)
return total_loss.item()/count, acc.item()/count
train_epoch(net,train_loader)
(0.0059344619750976565, 0.8926833333333334)
از آنجایی که این تابع بسیار عمومی است، میتوانیم بعداً از آن در نمونههای دیگرمان استفاده کنیم. تابع پارامترهای زیر را می گیرد:
شبکه عصبی
DataLoader، که داده ها را برای آموزش تعریف می کند
تابع ضرر که تابعی است که تفاوت بین نتیجه مورد انتظار و نتیجه تولید شده توسط شبکه را اندازه گیری می کند. در اکثر وظایف طبقه بندی NLLLoss استفاده می شود، بنابراین ما آن را به صورت پیش فرض در نظر می گیریم.
بهینه ساز، که یک الگوریتم بهینه سازی را تعریف می کند. سنتی ترین الگوریتم، گرادیان کاهشی تصادفی است، اما ما به طور پیش فرض از نسخه پیشرفته تری به نام Adam استفاده خواهیم کرد.
نرخ یادگیری سرعت یادگیری شبکه را مشخص می کند. در طول یادگیری، دادههای یکسانی را چندین بار ملاقات می کنیم و هر بار وزنها تنظیم میشوند. اگر نرخ یادگیری خیلی بالا باشد، مقادیر جدید دانش، از مقادیر قدیمی بازنویسی میشود و شبکه عملکرد بدی خواهد داشت. اگر میزان یادگیری خیلی کم باشد، فرآیند یادگیری بسیار کندی را به همراه دارد.
این چیزی است که ما هنگام آموزش انجام می دهیم:
- تغییر شبکه به حالت آموزشی (net.train())
- مرور تمام دستههای موجود در مجموعه داده و برای هر دسته موارد زیر را انجام می شود:
- محاسبه پیشبینیهای انجامشده توسط شبکه در این دسته (خروجی)
- محاسبه ضرر، که اختلاف بین مقادیر پیش بینی شده و مورد انتظار است
- تلاش برای حداقل رساندن تلفات با تنظیم وزن شبکه به حداقل (optimizer.step())
- محاسبه تعداد موارد به درستی پیش بینی شده (دقت)
این تابع میانگین تلفات هر مورد داده ( هر تصویر از MNIST)و دقت آموزش (درصد موارد به درستی حدس زده شده) را محاسبه و برمی گرداند. با مشاهده این تابع ضرر در حین آموزش می توان متوجه شد که آیا شبکه در حال بهبود است و از داده های ارائه شده یاد می گیرد یا خیر.
همچنین کنترل دقت در مجموعه داده آزمایشی (که دقت اعتبارسنجی نیز نامیده می شود) مهم است. یک شبکه عصبی خوب با پارامترهای زیاد می تواند با دقت مناسبی روی هر مجموعه داده آموزشی پیش بینی کند، اما ممکن است به سایر داده ها تعمیم ضعیفی داشته باشد. به همین دلیل است که در بیشتر موارد، بخشی از دادههای خود را کنار میگذاریم، و سپس به صورت دورهای بررسی میکنیم که مدل بر روی آنها چقدر خوب عمل میکند. در اینجا تابع ارزیابی شبکه در مجموعه داده آزمایشی است:
def validate(net, dataloader,loss_fn=nn.NLLLoss()):
net.eval()
count,acc,loss = 0,0,0
with torch.no_grad():
for features,labels in dataloader:
out = net(features)
loss += loss_fn(out,labels)
pred = torch.max(out,1)[1]
acc += (pred==labels).sum()
count += len(labels)
return loss.item()/count, acc.item()/count
validate(net,test_loader)
(0.033262069702148435, 0.9496)
مشابه تابع Train، میانگین تلفات و دقت را در مجموعه داده آزمایشی برمیگردانیم.
بیش برازش
به طور معمول هنگام آموزش یک شبکه عصبی، مدل را برای چندین دوره با رعایت دقت آموزشی و اعتبار سنجی آموزش می دهیم. در ابتدا، دقت آموزش و اعتبارسنجی باید افزایش یابد، زیرا شبکه الگوهای موجود در مجموعه داده را انتخاب می کند. با این حال، در برخی موارد ممکن است اتفاق بیفتد که دقت آموزش افزایش می یابد در حالی که دقت اعتبار سنجی شروع به کاهش می کند. این نشان دهنده برازش بیش از حد است، یعنی مدل در مجموعه داده های آموزشی شما به خوبی عمل می کند، اما در داده های جدید خیر.
def train(net,train_loader,test_loader,optimizer=None,lr=0.01,epochs=10,loss_fn=nn.NLLLoss()):
optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)
res = { 'train_loss' : [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
for ep in range(epochs):
tl,ta = train_epoch(net,train_loader,optimizer=optimizer,lr=lr,loss_fn=loss_fn)
vl,va = validate(net,test_loader,loss_fn=loss_fn)
print(f"Epoch {ep:2}, Train acc={ta:.3f}, Val acc={va:.3f}, Train loss={tl:.3f}, Val loss={vl:.3f}")
res['train_loss'].append(tl)
res['train_acc'].append(ta)
res['val_loss'].append(vl)
res['val_acc'].append(va)
return res
# Re-initialize the network to start from scratch
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784,10), # 784 inputs, 10 outputs
nn.LogSoftmax())
hist = train(net,train_loader,test_loader,epochs=5)
Epoch 0, Train acc=0.892, Val acc=0.893, Train loss=0.006, Val loss=0.006
Epoch 1, Train acc=0.910, Val acc=0.899, Train loss=0.005, Val loss=0.006
Epoch 2, Train acc=0.913, Val acc=0.898, Train loss=0.005, Val loss=0.006
Epoch 3, Train acc=0.915, Val acc=0.897, Train loss=0.005, Val loss=0.006
Epoch 4, Train acc=0.916, Val acc=0.897, Train loss=0.005, Val loss=0.006
در زیر تابع آموزشی است که می تواند برای انجام آموزش و اعتبارسنجی استفاده شود. دقت آموزش و اعتبارسنجی را برای هر دوره چاپ میکند، و همچنین تاریخچهای را برمیگرداند که میتوان از آن برای ترسیم ضرر و دقت روی نمودار استفاده کرد.
plt.figure(figsize=(15,5))
plt.subplot(121)
plt.plot(hist['train_acc'], label='Training acc')
plt.plot(hist['val_acc'], label='Validation acc')
plt.legend()
plt.subplot(122)
plt.plot(hist['train_loss'], label='Training loss')
plt.plot(hist['val_loss'], label='Validation loss')
plt.legend()
<matplotlib.legend.Legend at 0x7f798c2b12d0>
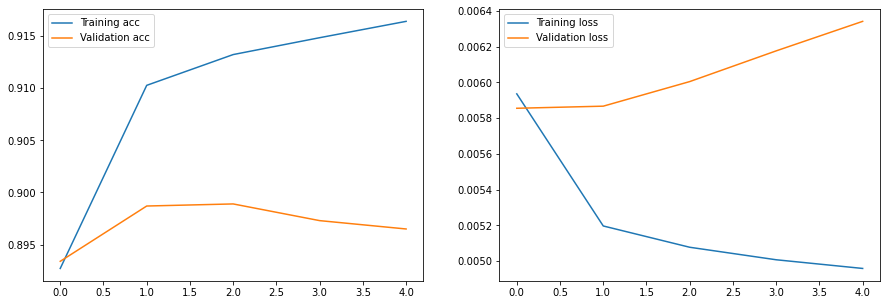
نمودار سمت چپ افزایش دقت آموزش را نشان میدهد (که مربوط به یادگیری شبکه برای طبقهبندی دادههای آموزشی بهتر و بهترمی شود)، در حالی که دقت اعتبارسنجی شروع به کاهش میکند. نمودار سمت راست ضرر آموزش و ضرر داده اعتبارسنجی را نشان می دهد، می توانید کاهش تابع ضرر آموزش (به معنی عملکرد بهتر) و افزایش تابع ضرر داده های اعتبارسنجی (به معنی عملکرد بدتر) را مشاهده کنید. این نمودارها نشان می دهد که مدل بیش از حد برازش شده است.
نمایش وزن شبکه
لایه متراکم در شبکه ما ,همان طور که قبلا گفتیم لایه خطی نامیده می شود، زیرا تبدیل خطی روی ورودی خود انجام می دهد که می تواند به صورت y=Wx+b تعریف شود که در آن W ماتریسی از وزن ها و b بایاس است. ماتریس وزن W در واقع مسئول کارهایی است که شبکه ما می تواند انجام دهد، یعنی تشخیص ارقام. در مورد مسئله کنونی ما، اندازه آن 784×10 است، زیرا 10 خروجی (یک خروجی برای هر رقم) برای یک تصویر ورودی تولید می کند.
بیایید وزن شبکه عصبی خود را نمایش دهیم و ببینیم که چگونه به نظر می رسند. وقتی شبکه پیچیدهتر از یک لایه باشد، تجسم نتایج به این شکل ممکن است دشوار باشد، زیرا در شبکههای پیچیده وزنها هنگام تجسم معنی چندانی ندارند. با این حال، در این مورد ما، هر یک از 10 بعد ماتریس وزن W با ارقام جداگانه مطابقت دارد، و بنابراین می توان برای مشاهده چگونگی تشخیص رقم تجسم کرد. به عنوان مثال، اگر بخواهیم ببینیم عدد ما 0 است یا خیر، رقم ورودی را در W[0] ضرب می کنیم و نتیجه را از نرمال سازی softmax عبور می دهیم تا به جواب برسیم.
در کد زیر، ابتدا ماتریس W را به متغیر weight_tensor وارد می کنیم. می توان آن را با فراخوانی متد net.parameters() (که W و b را برمی گرداند) و سپس فراخوانی next برای دریافت اولین پارامتر از دو پارامتر بدست آورد.
سپس هر بعد را مرور می کنیم، آن را به اندازه 28×28 تغییر شکل می دهیم و رسم می کنیم. می بینید که 10 بعد تانسور وزن تا حدودی شبیه شکل متوسط ارقامی است که طبقه بندی می کنند:
weight_tensor = next(net.parameters())
fig,ax = plt.subplots(1,10,figsize=(15,4))
for i,x in enumerate(weight_tensor):
ax[i].imshow(x.view(28,28).detach())

پرسپترون چند لایه
برای افزایش بیشتر دقت، ممکن است بخواهیم یک یا چند لایه پنهان را اضافه کنیم.
تصویری که یک شبکه چند لایه با یک لایه پنهان بین لایه ورودی و لایه خروجی را نشان می دهد
ساختار لایه های شبکه ما به شکل زیر خواهد بود:
نکته مهمی که در اینجا باید به آن توجه کرد تابع فعال سازی غیرخطی بین لایه ها است که ReLU نامیده می شود. معرفی آن توابع فعالسازی غیرخطی مهم است، زیرا یکی از دلایلی هستند که شبکههای عصبی به قدرت بالایی دست مییابند. در واقع، می توان از نظر ریاضی نشان داد که اگر یک شبکه فقط از یک سری لایه های خطی تشکیل شده باشد، اساساً معادل یک لایه خطی خواهد بود. بنابراین درج توابع غیر خطی در بین لایه ها مهم است!
ReLU ساده ترین تابع فعال سازی است که به صورت زیر تعریف می شود:
ReLU(x)={0xx<0x≥0
دیگر توابع فعال سازی مورد استفاده در یادگیری عمیق سیگموئید و tanh هستند، اما ReLU بیشتر در بینایی کامپیوتر استفاده می شود، زیرا می توان آن را به سرعت محاسبه کرد و استفاده از سایر توابع هیچ مزیت قابل توجهی ندارد.
این شبکه را می توان در PyTorch با این کد تعریف کرد:
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784,100), # 784 inputs, 100 outputs
nn.ReLU(), # Activation Function
nn.Linear(100,10), # 100 inputs, 10 outputs
nn.LogSoftmax(dim=0))
summary(net,input_size=(1,28,28))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Flatten: 1-1 [1, 784] --
├─Linear: 1-2 [1, 100] 78,500
├─ReLU: 1-3 [1, 100] --
├─Linear: 1-4 [1, 10] 1,010
├─LogSoftmax: 1-5 [1, 10] --
==========================================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
Total mult-adds (M): 0.08
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.32
Estimated Total Size (MB): 0.32
==========================================================================================
در اینجا ما از تابع summary() برای نمایش ساختار لایه به لایه یک شبکه با اطلاعات مفید دیگر استفاده می کنیم. به طور خاص، ما می توانیم ببینیم:
ساختار لایه به لایه شبکه و اندازه خروجی هر لایه
تعداد پارامترهای هر لایه و همچنین برای کل شبکه. هر چه شبکه پارامترهای بیشتری داشته باشد، نمونه های داده بیشتری باید برای جلوگیری از برازش بیش از حد آموزش داده شود.
بیایید ببینیم که چگونه تعداد پارامترها محاسبه می شود. لایه خطی اول دارای 784 ورودی و 100 خروجی است. لایه با W×x+b تعریف میشود که اندازه W 100×784 و b – 100 است. بنابراین تعداد کل پارامترهای این لایه 784×100+100=78500 است. به همین ترتیب، تعداد پارامترهای لایه دوم 100×10+10=1010 است. توابع فعال سازی و همچنین لایه های Flatten پارامتری ندارند
نحو دیگری وجود دارد که می توانیم از آن برای تعریف همان شبکه با استفاده از کلاس ها استفاده کنیم:
from torch.nn.functional import relu, log_softmax
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.flatten = nn.Flatten()
self.hidden = nn.Linear(784,100)
self.out = nn.Linear(100,10)
def forward(self, x):
x = self.flatten(x)
x = self.hidden(x)
x = relu(x)
x = self.out(x)
x = log_softmax(x,dim=0)
return x
net = MyNet()
summary(net,input_size=(1,28,28),device='cpu')
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Flatten: 1-1 [1, 784] --
├─Linear: 1-2 [1, 100] 78,500
├─Linear: 1-3 [1, 10] 1,010
==========================================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
Total mult-adds (M): 0.08
==========================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.32
Estimated Total Size (MB): 0.32
==========================================================================================
می بینید که ساختار شبکه عصبی مانند شبکه Sequential-defined است، اما این تعریف واضح تر است. شبکه عصبی سفارشی ما با یک کلاس به ارث رسیده از کلاس torch.nn.Module نشان داده می شود.
تعریف کلاس شامل دو بخش است:
در سازنده (init) تمام لایه هایی که شبکه ما خواهد داشت را تعریف می کنیم. این لایهها بهعنوان متغیرهای داخلی کلاس ذخیره میشوند و PyTorch بهطور خودکار میداند که پارامترهای آن لایهها باید هنگام آموزش بهینه شوند. در داخل، PyTorch از متد parameters() برای جستجوی تمام پارامترهای قابل آموزش استفاده می کند و nn.Module به طور خودکار تمام پارامترهای قابل آموزش را از همه ماژول های فرعی جمع آوری می کند.
ما روش فوروارد را تعریف می کنیم که محاسبات عبور رو به جلو شبکه عصبی ما را انجام می دهد. دراین مورد ما، ما با یک پارامتر تانسور x شروع میکنیم و به صراحت آن را از میان تمام لایهها و توابع فعالسازی عبور میدهیم، از flatten شروع تا لایه خطی نهایی به بیرون. هنگامی که شبکه عصبی خود را با نوشتن = net(x) روی برخی از داده های ورودی x اعمال می کنیم، روش فوروارد فراخوانی می شود.
در واقع، شبکههای Sequential به شیوهای بسیار مشابه نشان داده میشوند، آنها فقط فهرستی از لایهها را ذخیره میکنند و آنها را بهطور متوالی درگذر رو به جلو به کار میگیرند . در اینجا ما این شانس را داریم که این فرآیند را به طور واضح تر نشان دهیم، که در نهایت به ما انعطاف پذیری بیشتری می دهد. این یکی از دلایلی است که استفاده از کلاس ها برای تعریف شبکه های عصبی یک عمل توصیه شده و ارجح است.
اکنون می توانید سعی کنید این شبکه را دقیقاً با همان تابع آموزشی که در بالا تعریف کردیم، آموزش دهید:
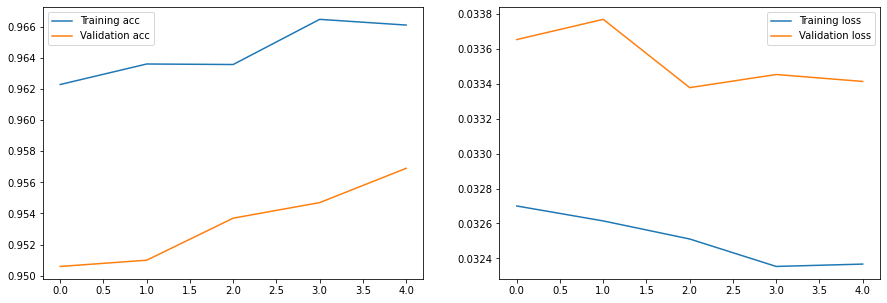
hist = train(net,train_loader,test_loader,epochs=5)
plot_results(hist)
Epoch 0, Train acc=0.962, Val acc=0.951, Train loss=0.033, Val loss=0.034
Epoch 1, Train acc=0.964, Val acc=0.951, Train loss=0.033, Val loss=0.034
Epoch 2, Train acc=0.964, Val acc=0.954, Train loss=0.033, Val loss=0.033
Epoch 3, Train acc=0.966, Val acc=0.955, Train loss=0.032, Val loss=0.033
Epoch 4, Train acc=0.966, Val acc=0.957, Train loss=0.032, Val loss=0.033
بردن
آموزش شبکه عصبی در PyTorch را می توان با یک حلقه آموزشی برنامه نویسی کرد. ممکن است فرآیند پیچیده ای به نظر برسد، اما درحقیقت باید یک بار آن را بنویسیم و بعداً می توانیم بدون تغییر آن، دوباره از این کد آموزشی استفاده کنیم.
می بینیم که شبکه های عصبی متراکم تک لایه و چند لایه عملکرد نسبتاً خوبی از خود نشان می دهند، اما اگر سعی کنیم آنها را در تصاویر دنیای واقعی اعمال کنیم، دقت آن خیلی بالا نخواهد بود. در بخش بعدی، مفهوم کانولوشن را معرفی خواهیم کرد که به ما امکان می دهد عملکرد بسیار بهتری برای تشخیص تصویر داشته باشیم.