
SIFT Flow: ارتباطات متراکم بین صحنه ها و کاربردهای آن
اکتبر 15, 2020آشکارسازی ساختمان در تصاویر ماهواره ای
اکتبر 19, 2020sift flow algorithm | الگوریتم جریان سیفت
SIFT یک توصیفگر محلی برای توصیف اطلاعات شیب محلی است . در مقاله اصلی ، توصیفگر SIFT یک بازنمایی تنک ویژگی است که هم از استخراج و هم از کشف ویژگی تشکیل شده است. در این مقاله ، ما فقط از مولفه استخراج ویژگی استفاده می کنیم. برای هر پیکسل در یک تصویر ، همسایگی آن را (به عنوان مثال 16 × 16) به یک آرایه سلول 4 × 4 تقسیم می کنیم، جهت گیری را به 8 قسمت در هر سلول تقسیم می کنیم و یک بردار 4 × 4 × 8 = 128 بعدی به عنوان نمایش(بازنمایی) SIFT برای یک پیکسل به دست می آوریم. ما به این توصیفگر SIFT هر پیکسل تصویر SIFT می گوییم.
برای تجسم سازی تصاویر(توصیفگر) SIFT ، ما سه مولفه اصلی و مهم توصیفگرهای SIFT را از مجموعه ای از تصاویر محاسبه می کنیم و سپس این مولفه های اصلی را به مولفه های اصلی فضای RGB ترسیم می کنیم ، همانطور که در شکل 2 نشان داده شده است. از طریق طرح یک توصیف گر 128 بعدی SIFT به یک فضای فرعی 3 بعدی ، ما قادر به محاسبه تصویر SIFT از یک تصویر RGB در شکل 2 (c) و تجسم آن در (d) هستیم. در این تجسم سازی، پیکسل هایی که رنگ مشابه دارند ممکن است به این معنی باشد که ساختارهای تصویر محلی مشابهی دارند. توجه داشته باشید که این طرح فقط برای تجسم است. در جریان SIFT ، از کل 128 بعد برای مطابقت استفاده می شود.

توجه داشته باشید که حتی اگر این تجسم SIFT تار به نظر برسد ، همانطور که در شکل بالا (d) نشان داده شده است ، تصاویر SIFT در واقع از وضوح مکانی بالایی برخوردار هستند ، همانطور که در شکل زیر اشاره شده است. ما یک تصویر را با یک لبه افقی طراحی کردیم (شکل(a)) ، و اولین مولفه تصویر SIFT (a) را در (c) نشان دادیم. از آنجا که هر سطر در (a) و (c) یکسان است ، ما به ترتیب سطر وسط (a) و (c) را در (b) و (d) رسم می کنیم. واضح است که ، تصویر SIFT حاوی یک لبه تیز که با توجه به لبه تیز در تصویر اصلی است.

هدف تطبیق
ما جریان SIFT را همانند جریان نوری به استثنای تطابق توصیف گرهای SIFT به جای مقادیر RGB ، فرموله می کنیم. بنابراین ، تابع هدف جریان SIFT بسیار شبیه جریان نوری است. بگذارید p = (x ، y) مختصات شبکه تصاویر باشد و w (p) = (u (p) ، v (p)) بردار جریان در p باشد. ما فقط اجازه می دهیم که u (p) و v (p) عدد صحیح باشند و فرض می کنیم به ترتیب L حالت های ممکن برای u (p) و v (p) وجود داشته باشد. بگذارید s1 و s2 دو تصویر SIFT باشند که می خواهیم مطابقت داشته باشند. مجموعه ε شامل تمام همسایگی های مکانی است (از سیستم چهار همسایه استفاده می شود). تابع انرژی برای جریان SIFT به شرح زیر است:
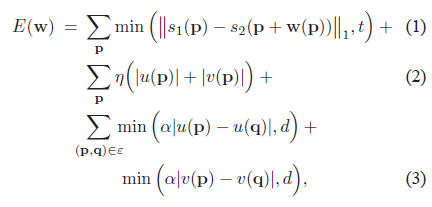
که شامل یک ترم داده ، ترم جابجایی کوچک و ترم نرمی (نظم مکانی) است.ترم داده در خط 1 توصیفگرهای SIFT را مجبور میکند که همراه با بردار جریان w (p) مطابقت داده می شود. ترم جابجایی کوچک در خط 2 بردارهای جریان را محدود می کند تا حد ممکن کوچک شوند و هیچ اطلاعات دیگری در دسترس نداشته باشند. ترم صافی در خط 3 بردارهای جریان پیکسل های مجاور را مجبور می کند تا مشابه باشند. در این تابع هدف ، نرم کوتاه شده L1 در هر دو ترم داده و ترم صافی برای محاسبه انصباق های اشتباه و ناپیوستگی های جریان به ترتیب با t و d به عنوان آستانه استفاده می کند.
ما برای بهینه سازی تابع هدف از انتشار باورهای حلقه ای دو لایه به عنوان الگوریتم پایه استفاده می کنیم. متفاوت از فرمول معمول جریان نوری ، ترم صافی در معادله فوق جدا شده است ، که به ما امکان می دهد جریان افقی u (p) را از جریان عمودی v (p) در عبور پیام جدا کنیم ، همانطور که توسط [ 7] پیشنهاد شده است .در نتیجه ، پیچیدگی الگوریتم در یک تکرار عبور پیام از O (L^4) به O (L^2) کاهش می یابد. فاکتور گراف مدل ما در شکل 4 نشان داده شده است. ما یک لایه افقی u و لایه عمودی v با شبکه دقیقا مشابه درست می کنیم ، با ترم داده پیکسل های متصل در همان مکان. در عبور پیام ، ما ابتدا پیام های درون لایه را در u و v به طور جداگانه به روز می کنیم ، و سپس پیام های بین لایه را بین u و v به روز می کنیم. از آنجا که شکل عملکردی تابع هدف نرم L1 کوتاه شده دارد ، از تابع تبدیل فاصله برای کاهش بیشتر پیچیدگی و انتشار باور متوالی (BP-S) [9] برای همگرایی بهتر استفاده می کنیم .


طرح تطبیق درشت تا ریز
با وجود سرعت بالا ، بهینه سازی مستقیم تابع هدف با استفاده از مقیاس های انتشار باور دو لایه با توجه به بعد تصویر ، ضعیف است. در جریان SIFT ، یک پیکسل در یک تصویر می تواند به معنای واقعی کلمه با هر پیکسل در تصویر دیگر مطابقت داشته باشد. فرض کنید تصویر دارای h^2 پیکسل و سپس L ≈ h است و پیچیدگی زمانی و مکانی این BP دو لایه برابر O (h^4) است. به عنوان مثال ، زمان محاسبه تصاویر 145 × 105 با پنجره جستجوی 80 × 80 50 ثانیه است. پردازش یک جفت تصویر 256 × 256 با حافظه 16 گیگابایتی برای ذخیره ترم داده , به بیش از دو ساعت زمان نیاز دارد.
برای رفع اشکال عملکرد ، ما یک طرح تطبیق جریان SIFT درشت تا ریز طراحی کردیم که عملکرد را به طور قابل توجهی بهبود می بخشد. ایده اصلی به طور تقریبی جریان در سطح درشت شبکه تصویرتخمین می زند ، سپس به تدریج انتشار و تصفیه جریان از درشت به ریز است. این روش در شکل 6 نشان داده شده است. برای سادگی ، از s برای نشان دادن s1 و s2 استفاده می کنیم. هرم SIFT {s^ (k)} ایجاد می شود ، جایی که s (1) = s و s (k + 1) صاف و از s^ (k) نمونه برداری می شود. در هر سطح هرم k ، مختصات پیکسل pk بگذارید برای مطابقت باشد ، ck انحراف یا مرکز پنجره جستجو باشد و w (pk) بهترین مطابقت از BP باشد. در سطح بالای هرم s (3) ، پنجره جستجو در p3 (c3 = p3) با اندازه m × m در مرکز قرار می گیرد ، جایی که m عرض (ارتفاع) s (3) است. پیچیدگی BP در این سطح O (m^4) است. پس از همگرایی BP ، سیستم بردار جریان بهینه w (p3) را به سطح بعدی (ریزتر) منتقل می کند تا c2 باشد که در آن پنجره جستجوی p2 در مرکز است. اندازه این پنجره جستجو n = 11 با n × n ثابت شده است. این روش از s (3) تا s (1) تکرار می شود تا بردار جریان w (p1) تخمین زده شود. پیچیدگی این الگوریتم درشت به ریز O (h^2 log h) است ، سرعت قابل توجهی بالاتر از O (h^4) است. علاوه بر این ، ما η دو برابر می کنیم و α و d را حفظ می کنیم زیرا الگوریتم به سطح بالاتری از هرم در به حداقل رساندن انرژی می رسد.با استفاده از طرح تطبیق درشت و ریز پیشنهاد شده و تابع تبدیل فاصله اصلاح شده ، تطبیق بین دو تصویر 256 × 256 در یک ایستگاه کاری با دو پردازنده چهار هسته ای 2.67 گیگاهرتز Intel Xeon و 32 گیگابایت حافظه ، با اجرای C ++ 31 ثانیه طول می کشد.


یک سوال طبیعی این است که آیا طرح تطبیق درشت تا ریز می تواند به حداقل انرژی مشابه طرح تطبیق معمولی برسد (فقط با استفاده از یک سطح). ما به طور تصادفی 200 جفت تصویر را برای تخمین جریان SIFT انتخاب کردیم و حداقل انرژی بدست آمده را با استفاده از طرح درشت از ریز و طرح عادی (غیر درشت از ریز) به ترتیب بررسی کردیم. برای این تصاویر 256 × 256 ، میانگین زمان جریان SIFT برای درشت به ریز 31 ثانیه است ، در حالی که برای مطابقت معمولی به طور متوسط 127 دقیقه است. طرح درشت تا ریز نه تنها به طور چشمگیری سریعتر اجرا می شود ، بلکه در مقایسه با الگوریتم تطبیق معمولی همانطور که در شکل 8 نشان داده شده است ، انرژی کمتری را به دست می آورد. این با آنچه درمجموعه جریان نوری کشف شده سازگار است: جستجوی درشت به ریز نه تنها سرعت محاسبات را افزایش می دهد بلکه به راه حل های بهتری نیز منجر می شود.

همسایگی جریان SIFT
از لحاظ تئوری ، برای تخمین یک ارتباطات می توانیم جریان نوری را به دو تصویر دلخواه اعمال کنیم ، ممکن است ارتباطات معنی داری نداشته باشیم اما اگر این دو تصویر از دسته های صحنه متفاوت باشند . در حقیقت ، حتی هنگامی که در یک توالی ویدئویی جریان نوری را به دو فریم مجاور اعمال می کنیم ، ما از زمان نمونه برداری متراکم را تا هم پوشانی قابل توجهی بین دو فریم همسایه وجود در نظر می گیریم. به همین ترتیب ، در جریان SIFT ، هنگام پرس و جو از یک پایگاه داده بزرگ با ورودی ، همسایگی یک تصویر را به عنوان نزدیکترین همسایه تعریف می کنیم. در حالت ایده آل ، اگر پایگاه داده به اندازه کافی بزرگ و متراکم باشد که تقریباً هر تصویر ممکن در جهان را در خود داشته باشد ، نزدیکترین همسایگان با اشتراک ساختارهای محلی مشابه ، به تصویر پرس و جو نزدیک می شوند. این شبیه سازی زیر را در قیاس با جریان نوری ایجاد می کند:
| Dense sampling in time | : | optical flow |
| Dense sampling in the space of all images | : | SIFT flow |
از آنجا که فرض بر این است که نمونه برداری متراکم از دامنه زمان امکان ردیابی را دارد ، فرض بر این است که نمونه برداری متراکم (در بخشی از) فضای تصاویر جهان امکان تراز صحنه را دارد. برای اینکه این تشبیه را امکان پذیر کنیم ، ما یک پایگاه داده بزرگ متشکل از 102206 فریم از 731 فیلم ، بیشتر از صحنه های خیابان را جمع آوری می کنیم. مشابه دامنه زمان ، ما “فریم های مجاور” یک تصویر پرس و جو را به عنوان N نزدیکترین همسایه آن در این پایگاه داده تعریف می کنیم. جریان SIFT سپس بین تصویر پرس و جو و N نزدیکترین همسایه آن برقرار می شود.
برای یک تصویر پرس و جو ، ما از یک تکنیک سریع نمایه سازی برای بازیابی نزدیکترین همسایگان خود استفاده می کنیم که با استفاده از جریان SIFT بیشتر تراز خواهد شد. به عنوان یک جستجوی سریع ، از هیستوگرام تطبیق مکانی ویژگی های SIFT کوانتیزه شده استفاده می کنیم [32]. ابتدا ، با اجرای K-means بر روی 5000 توصیف کننده SIFT که به طور تصادفی از بین همه فریم های ویدیویی مجموعه داده ما انتخاب شده اند ، یک فرهنگ لغت از 500 کلمه تصویری ایجاد می کنیم. سپس ، هیستوگرام کلمات تصویری در هرم مکانی دو سطح ، بدست می آیند و از تقاطع هیستوگرام برای اندازه گیری شباهت بین دو تصویر استفاده می شود.